
SQL Server 2014 実践シリーズ (HTML 版)
「No.1 インメモリ OLTP 機能の実践的な利用方法」
松本美穂と松本崇博が執筆した SQL Server 2014 実践シリーズの「No.1 インメモリ OLTP 機能の実践的な利用方法」の HTML 版です。 日本マイクロソフトさんの Web サイトで Word または PDF 形式でダウンロードできますが、今回、HTML 版として公開する許可をいただきましたので、ここに掲載いたします。[2015年12月29日]
2.16 ネイティブ コンパイル SP での SELECT 時の BIN2 照合順序
ネイティブ コンパイル SP 内の SELECT ステートメントで、文字列の比較や並べ替えを行う場合には、BIN2 照合順序が必須になります。
◆ 文字列の比較や並べ替えは、BIN2 照合順序が必要
ネイティブ コンパイル SP では、BIN2 照合順序ではない文字データ列で比較演算を行おうとすると、次のようにエラーになります。
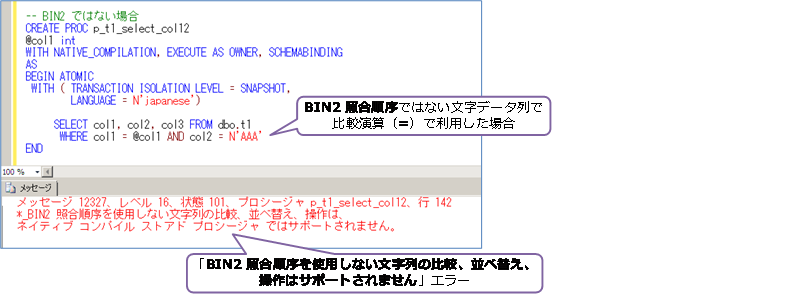
データベースの照合順序が Japanese_CI_AS の場合は、列の照合順序も既定で Japanese_CI_AS になるので、このようなエラーになります。
このエラーは、次のように COLLATE 句を付けることで回避することが可能ですが、この場合は、Index Scan(Index Seek ではなく、インデックスの全スキャン)になってしまうので、お勧めの方法ではありません。

お勧めの方法は、テーブルの作成時に、列の照合順序を Japanese_BIN2 などへ変更しておくことですが、これを利用する場合の注意点もあるので、後述します。
◆ Japanese_BIN2 への変更が必要な列 ~ PK/インデックスにも必須 ~
メモリ最適化テーブルでは、PRIMARY KEY 制約や、インデックスを付与する列には、BIN2 照合順序を使用するのが必須になります。また、上の例のように、ネイティブ コンパイル SP 内で比較演算(=)や並べ替え(ORDER BY)操作を行う場合にも、BIN2 照合順序が必須になります。
したがって、既存のディスク ベースのテーブルで char 型の PRIMARY KEY を利用している場合には、メモリ最適化テーブルへ移行するにあたって、多くの列で BIN2 照合順序への変更が発生することになります。今回のポイントカード システムでは、カードID やカード種別、MessageID などで char 型の PRIMARY KEY を利用していたので、全て Japanese_BIN2 照合順序へ変更しました。
◆ Japanese_BIN2 へ変更した場合の注意点 ~大文字・小文字の区別など~
Japanese_BIN2 照合順序へ変更した場合には、カードIDや MessageID などのように、格納されているデータが数字(0、1、2 など)のみである場合は、特に問題はありませんが、カード種別のように英数字(A1 や A2 など、英語が混ざっている場合)や、日本語を格納している場合には、次のことに注意する必要があります。
まず、BIN2 ではなく、Japanese_CI_AS(既定値)を利用している場合は、文字を比較するときに、次のように動作します。
- 大文字と小文字を区別しない(CI:Case Insensitive)
- アクセントを区別する(AS:Accent Sentitive)
- カタカナとひらがなを区別しない(KI:Kana Insensitive)
- 半角と全角を区別しない(WI:Wide Insensitive)
Japanese_CI_AS では、大文字と小文字を区別しないので、「A1」も「a1」も同じデータとして処理をします。したがって、カード種別に「A1」というデータが格納されている場合に、次のように「a1」で検索しても、データを取得することができます。
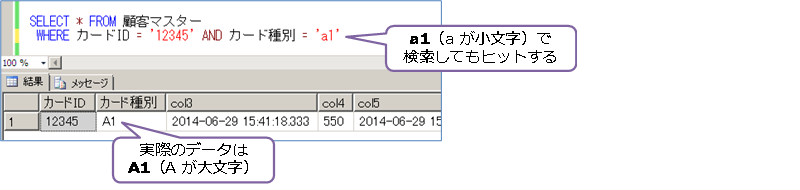
これに対して、Japanese_BIN2 では、バイナリ(文字コード)で文字の比較を行うので、上記をすべてを区別する(CS、AS、KS、WS に相当する)形に変わります。実際に格納されているデータが「A1」であれば、「a1」で検索すると、データを取得することができません。

このように、Japanese_BIN2 では、大文字と小文字を厳密に区別するようになり、カタカナとひらがなも区別、半角と全角も区別するようになるので、アプリケーション側で、意図的に大文字と小文字を区別しないような検索などを行っている場合には、アプリケーションの修正が必要になります。
◆ データの格納時に大文字・小文字を統一してしまう
Japanese_BIN2 を利用して、大文字と小文字を区別しない検索を行いたい場合には、データの格納時(INSERT や UPDATE 時)に、大文字または小文字を統一してしまうという方法がお勧めです。例えば、「カード種別」列のデータであれば、データを INSERT するときに、次のように UPPER 関数(.NET なら ToUpper メソッド)で大文字に統一してしまいます。
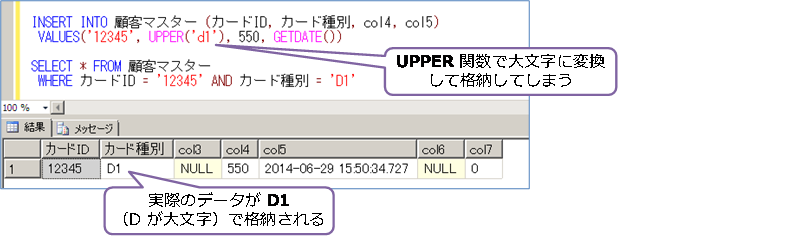
このようにデータを格納するときに、大文字か小文字のどちらかに統一をしてしまえば、検索をするときにも、同じ処理をすることで、大文字と小文字を区別することなく、データを取得できるようになります。

このように、格納するデータをどちらかに統一しておけば、検索時に入力された値を、その統一した値へ変換することで、大文字と小文字を区別しない検索が行えるようになります。
大文字・小文字を区別しない検索方法としては、次のように列データに対して、UPPER 関数をかける方法もあります。
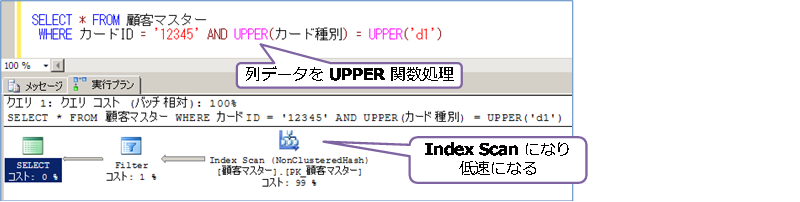
このように、列データに対して関数処理を行ってしまう場合は、インデックスが有効利用されず(Index Seek でのピンポイント検索ができなくなり)、Index Scan(インデックスの全スキャン)での検索になってしまうので、非常に低速になります。
したがって、大文字と小文字を区別しない検索を行いたい場合には、本文中で説明したようにデータの格納時に、どちらかへ統一するという方法がお勧めになります。
今回のポイントカード システムでは、カードID や MessageID などは、数値データのみが格納されているにも関わらず、char データ型を利用していますが、数値データのみが格納される場合は、int や bigint、decimal など数値系のデータ型を利用するのがお勧めになります。
例えば、char(16) で 16桁分のデータを格納するには、16バイトが必要になりますが(nchar(16) なら 32バイトが必要)、bigint であれば 8バイトで済みます。その分、メモリ使用量を削減することができるので、数値データのみの場合は、数値データ型へ変更できないか検討してみることをお勧めします。
数値データに意味があって(例えば、数値の先頭4桁を企業を識別するために利用しているなど)、char データ型を利用している、という場合も多いと思いますが(弊社のお客様でもそういった利用方法がほとんどです)、性能面を考慮すると、できる限り小さいデータ型を選択するのがお勧めです。
今回のポイントカード システムでは、char(1) の列がありますが、これはフラグ列です(状態に応じて、0 か 1 のどちらかがセットされる列)。このような char(1) のフラグ列は、多くの方が利用しているのではないでしょうか(弊社のお客様にもたくさんいらっしゃいます)。
フラグ列が、2種類の状態しか格納しない(0 と 1 や、1 と 2 など、どちらかの値しかとらない)ような場合には、bit データ型を利用するのがお勧めです。char(1) では 1バイトを消費しますが(nchar(1) なら 2バイト消費)、bit 型であれば 1ビットで済むからです。その分、メモリ使用量を削減することができるので、できる限り小さいデータ型を利用することをお勧めします。


SQL Server 2016 の教科書(ソシム)



ASP.NET でいってみよう
第7刷 16,500 部発行
SQL Server 2000 でいってみよう
第12刷 28,500 部発行

SQL Server 2014 CTP2 インメモリ OLTP 機能の概要(Amazon Kindle 書籍)
(公開活動などのお知らせ)
第60回:SQL Server 2017 自習書 No.3「SQL Server 2017 Machine Learning Services」のご案内
第59回:SQL Server 2017 自習書 No.2「SQL Server 2017 on Linux」のご案内
第58回:SQL Server 2017 自習書 No.1「SQL Server 2017 新機能の概要」のご案内
第57回:SQL Server 2017 RC 版とこれまでのドキュメントのまとめ
第56回:「SQL Server 2016 への移行とアップグレードの実践」完成&公開!
第55回:書籍「SQL Server 2016の教科書 開発編」(ソシム)が発刊されました
第54回:「SQL Server 2016 プレビュー版 Reporting Services の新機能」自習書のお知らせ
第 53 回:SQL Server 2016 Reporting Services の新しくなったレポート マネージャーとモバイル レポート機能
第 52 回:SQL Server 2016 の自習書を作成しました!
第 51 回:PASS Summit と MVP Summit で進化を確信!
第 50 回:新しくなった Power BI(2.0)の自習書を作成しました!
第49 回:Excel 2016 の Power Query を使う
第 48 回:新しくなった Microsoft Power BI ! 無料版がある!!
第 47 回:「Microsoft Azure SQL Database 入門」 完成&公開!
第 46 回:Microsoft Power BI for Windows app からの Power BI サイト アクセス
第 45 回:Power Query で取得したデータを PowerPivot へ読み込む方法と PowerPivot for Excel 自習書のご紹介
第44回:「SQL Server 2014 への移行とアップグレードの実践」ドキュメントを作成しました
第43回:SQL Server 2014 インメモリ OLTP 機能の上級者向けドキュメントを作成しました
第42回:Power Query プレビュー版 と Power BI for Office 365 へのクエリ保存(共有クエリ)
第41回:「SQL Server 2014 CTP2 インメモリ OLTP 機能の概要」自習書のお知らせです
第40回: SQL Server 2012 自習書(HTML版)を掲載しました
第39回: Power BI for Office 365 プレビュー版は試されましたか?
第38回: SQL Server 2014 CTP2 の公開
第37回: SQL Server 2014 CTP1 の自習書をご覧ください
第36回: SQL Server 2014 CTP1 のクラスター化列ストア インデックスを試す
第35回: SQL Server 2014 CTP1 のインメモリ OLTP の基本操作を試す
第34回: GeoFlow for Excel 2013 のプレビュー版を試す
第33回: iPad と iPhone からの SQL Server 2012 Reporting Servicesのレポート閲覧
第32回: PASS Summit 2012 参加レポート
第31回: SQL Server 2012 Reporting Services 自習書のお知らせ
第30回: SQL Server 2012(RTM 版)の新機能 自習書をご覧ください
第29回: 書籍「SQL Server 2012の教科書 開発編」のお知らせ
第26回: SQL Server 2012 の Power View 機能のご紹介
第25回: SQL Server 2012 の Data Quality Services
第24回: SQL Server 2012 自習書のご案内と初セミナー報告
第23回: Denali CTP1 が公開されました
第22回 チューニングに王道あらず
第21回 Microsoft TechEd 2010 終了しました
第20回 Microsoft TechEd Japan 2010 今年も登壇します
第19回 SQL Server 2008 R2 RTM の 日本語版が公開されました
第18回 「SQL Azure 入門」自習書のご案内
第17回 SQL Server 2008 自習書の追加ドキュメントのお知らせ
第16回 SQL Server 2008 R2 自習書とプレビュー セミナーのお知らせ
第15回 SQL Server 2008 R2 Reporting Services と新刊のお知らせ
第14回 TechEd 2009 のご報告と SQL Server 2008 R2 について
第13回 SQL Server 2008 R2 の CTP 版が公開されました
第12回 MVP Summit 2009 in Seattle へ参加