
SQL Server 2014 実践シリーズ (HTML 版)
「No.1 インメモリ OLTP 機能の実践的な利用方法」
松本美穂と松本崇博が執筆した SQL Server 2014 実践シリーズの「No.1 インメモリ OLTP 機能の実践的な利用方法」の HTML 版です。 日本マイクロソフトさんの Web サイトで Word または PDF 形式でダウンロードできますが、今回、HTML 版として公開する許可をいただきましたので、ここに掲載いたします。[2015年12月29日]
4.5 SELECT の取得データ件数が異なる場合の性能差
キー列(PRIMARY KEY)を利用した検索(SELECT ステートメント)の性能効果に関しては、第2章のポイントカード システムで確認しているので、ここでは単純なテーブルを利用して、取得するデータ件数が異なる場合の SELECT ステートメントの性能効果を確認してみます。次のパターンを確認してみました。
- SELECT の取得件数が約 5件の場合(シングル実行、100万回実行時)
- SELECT の取得件数が約 100件の場合(シングル実行、50万回実行時)
- SELECT の取得件数が約 1万件の場合(シングル実行、500回実行時)
いずれも WHERE 句で「=」演算子で検索を行って、その結果件数が異なる場合の性能を確認してみました。結果は、次のとおりです。
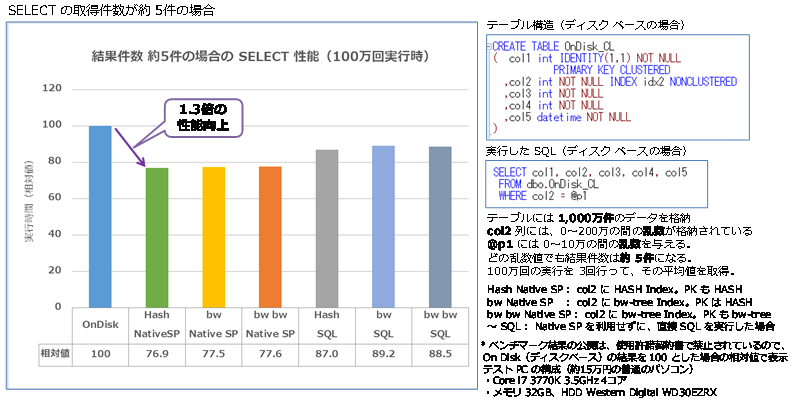
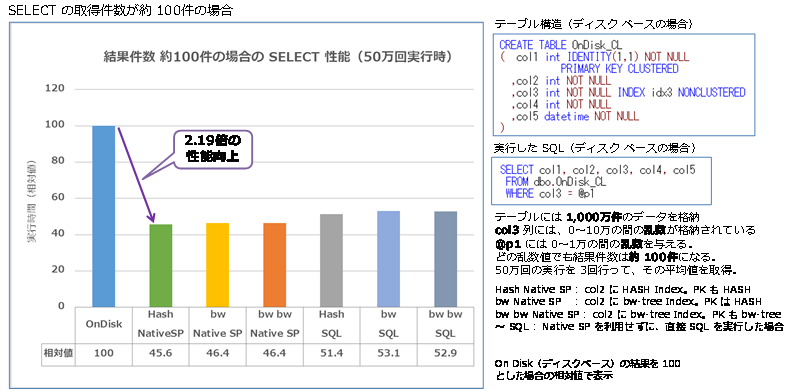
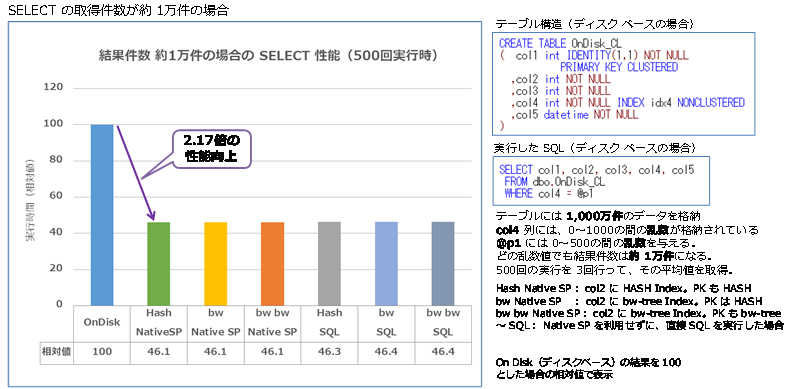
結果は、約5件の結果が返る場合に 1.3倍、約100件の結果が返る場合に 2.19倍、約1万件の結果が返る場合に 2.17倍となり、いずれもディスク ベースよりも性能向上することを確認できました。このように、インメモリ OLTP は、「=」演算子を利用した検索には強いことを確認することができました。また、今回のテストはシングル実行でしたが、インメモリ OLTP では、SELECT ステートメントがロック待ちおよびラッチ待ちになることがないので、多重度が上がって、更新系のステートメントと同時実行される状況では、さらに SELECT ステートメントの性能が向上することになります。
◆ 検証の詳細
この検証の詳細は、次のとおりです。
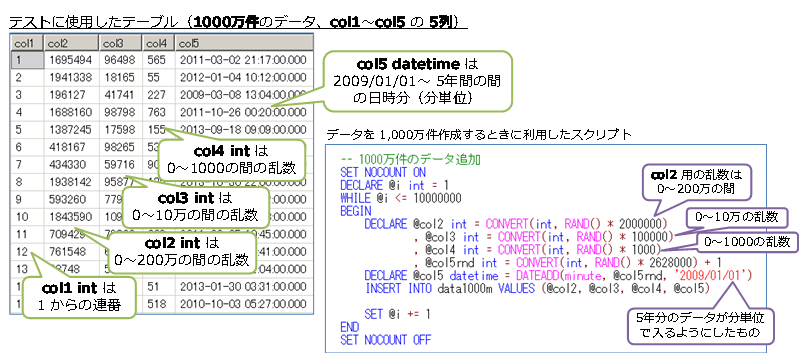
テストで使用したテーブルには、1,000万件のデータ(ディスク ベースもインメモリ OLTPも同じデータ)を格納して、col1(int)には 1からの連番(IDENTITY)、col2(int)には 0~200万の間の乱数、col3(int)には 0~10万の間の乱数、col4(int)には 0~1,000の間の乱数、col5(datetime)には 2009/01/01 以降の 5年分のデータを分単位(2,628,000通り)で格納(乱数で分ごとに 4~5件のデータが格納)されるようにしています。
このように乱数を利用することで、col2 で検索した場合には約5件、col3 で検索した場合には約100件、col4 で検索した場合には約1万件の結果が返るようになります。
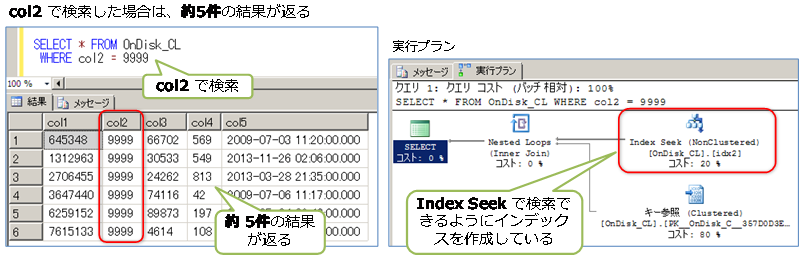
また、col2 で検索する場合には、テーブル構造を次のように変更して、col2 列へインデックスを作成し、Index Seek で検索できるようにしています。
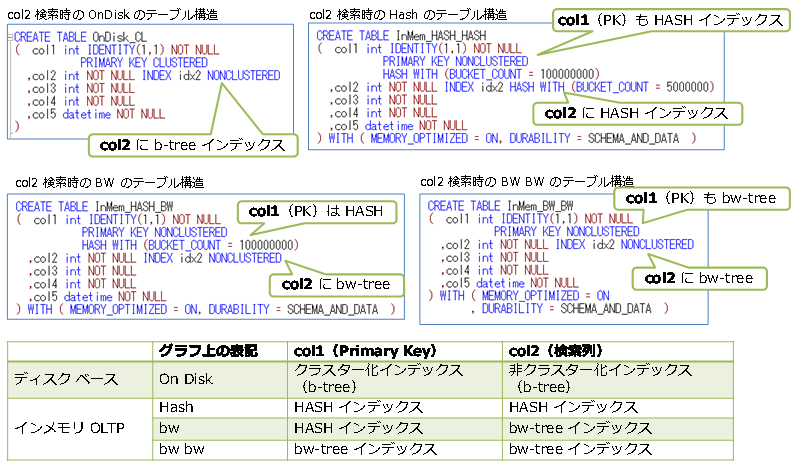
ディスク ベースのテーブルは、従来ながらの b-tree インデックス、インメモリ OLTP では、HASH または bw-tree インデックスを作成して、性能に違いが出るのかも確認してみました。
ネイティブ コンパイル SP は、次のように作成しています。

実際に、ネイティブ コンパイル SP や SQL ステートメントを実行する部分には、.NET(VB.NET と ADO.NET)を利用して、次のようなコードを記述しています。
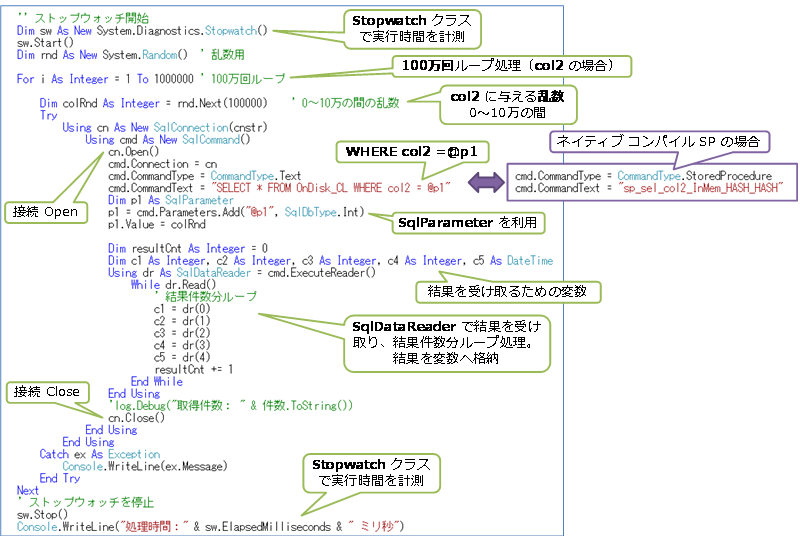
col2 の検索では、For ループで 100万回繰り返し実行を行って、col2 へ与える値(@p1)には Random クラスで 0~10万の間の乱数を生成したものを利用することで、同じ値での検索にならないようにしています。また、接続(SqlConnection)の Open と Close を入れたり、検索結果を変数へ格納したりすることで、より実際のアプリケーションに近い形の検索になるようにしています。
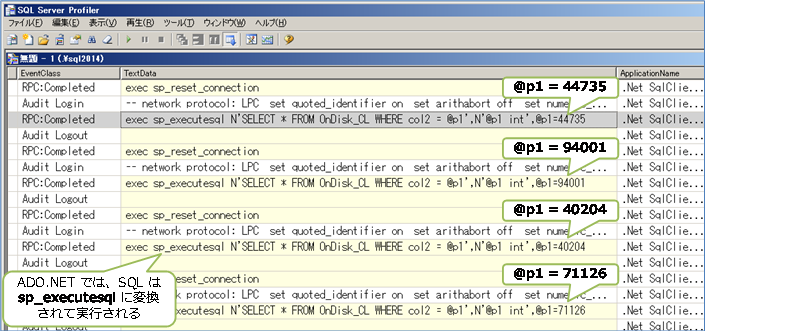
このコードを実行したときを SQL Server Profiler ツールでキャプチャすると、次のように col2 へ与える値(@p1)に乱数がセットされていることを確認することができます。
また、実行時間の測定には、Stopwatch クラスを利用してします(後述しますが、Stopwatch クラスでは、ミリ秒未満の計測=マイクロ秒単位での計測をすることができません。今回のように何万回と SQL ステートメントを実行する場合の計測であれば問題ありませんが、単一/1回のステートメントを実行する場合の計測には利用することができません。∵1回のステートメントの実行ではマイクロ秒レベルで完了してしまうため)。
◆ col3 列の検索の場合(約 100件の結果が返る)
col3 で検索した場合には約100件の結果が返るようにしています。
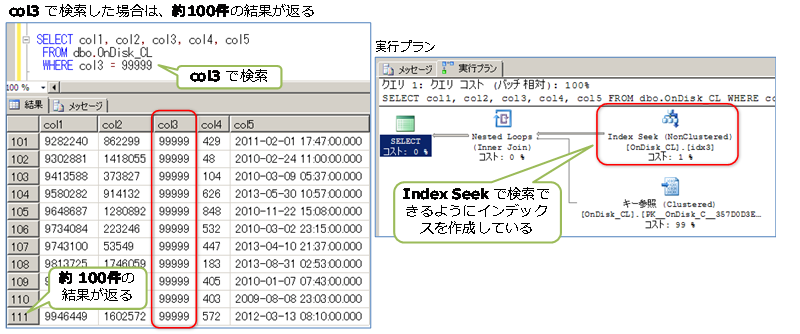
また、col3 で検索する場合には、テーブル構造を次のように変更して、col3 列へインデックスを作成し、Index Seek で検索できるようにしています。
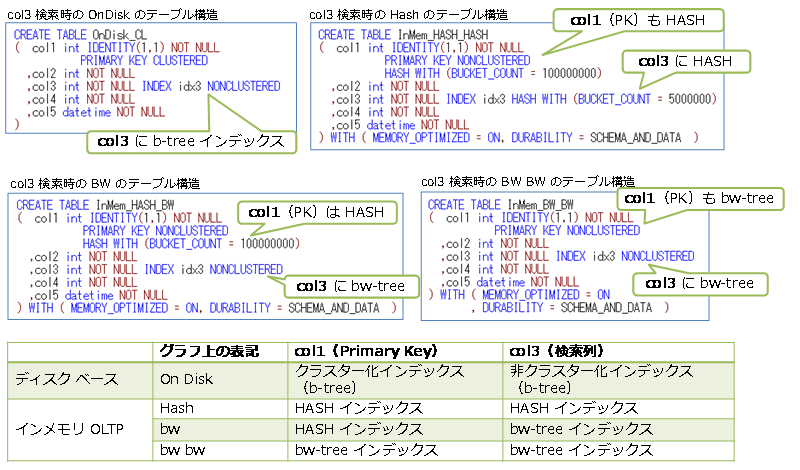
ネイティブ コンパイル SP は、次のように作成しています。

実際に、ネイティブ コンパイル SP や SQL ステートメントを実行する部分は、前述の .NET コードと同じものを利用しています。
◆ col4 列の検索の場合(約 1万件の結果が返る)
col4 で検索した場合には約1万件の結果が返るようにしています。
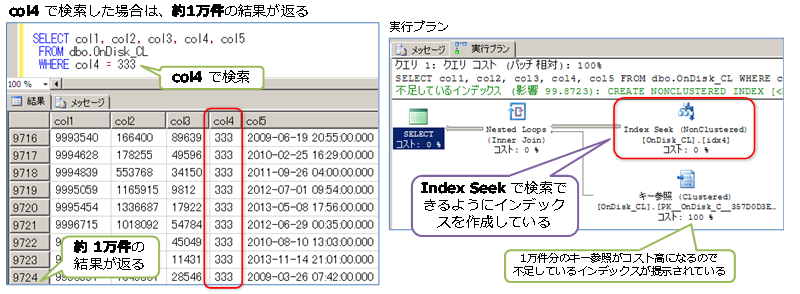
また、col4 で検索する場合には、テーブル構造を次のように変更して、col4 列へインデックスを作成し、Index Seek で検索できるようにしています。
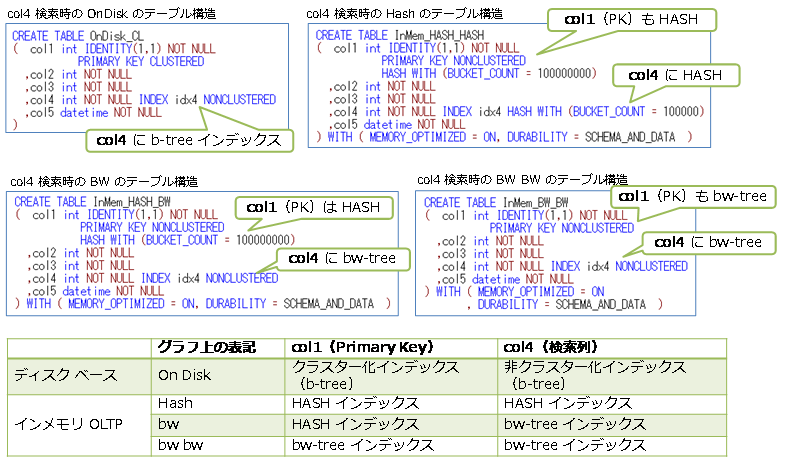
ネイティブ コンパイル SP は、次のように作成しています。

実際に、ネイティブ コンパイル SP や SQL ステートメントを実行する部分は、前述の .NET コードと同じものを利用しています。
◆ 検証のまとめ ~SELECT の取得データ件数の違い~
検証結果をまとめると、次のようになります。
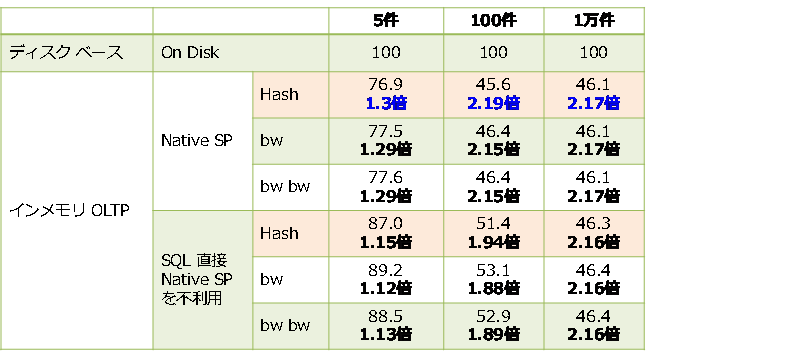
Native SP Hash では、約5件の結果が返る場合に 1.3倍、約100件の結果が返る場合に 2.19倍、約1万件の結果が返る場合に 2.17倍となり、どれもディスク ベースよりも性能向上することを確認できました。このように、インメモリ OLTP は、「=」演算子を利用した検索には強いことを確認することができました。
検索列に HASH インデックスを利用するか、bw-tree インデックスを利用するかでは、HASH インデックスのほうが若干速い程度で、ほとんど差が出ないことも確認することができました(後述しますが、bw-tree インデックスは、範囲スキャンに強いという特性があります)。
また、PRIMARY KEY に bw-tree インデックスを利用した場合(表の bw bw)と HASH インデックスを利用した場合(表の bw)も、大きな差は出ないことを確認することができました。
また、今回のテストはシングル実行でしたが、インメモリ OLTP では、SELECT ステートメントがロック待ちおよびラッチ待ちになることがないので、多重度が上がって、更新系のステートメントと同時実行される状況では、さらに SELECT ステートメントの性能が向上することになります。
◆ ハッシュ インデックスのチェーンの長さ
BUCKET_COUNT(バケット数)については後述しますが、HASH インデックスでは、十分な BUCKET_COUNT を設定している場合には、同じ値が、同じハッシュ値になって、チェーンが長くなります。

チェーンの長さは、次のように「dm_db_xtp_hash_index_stats」動的管理ビューを利用することで確認することができます。
-- object_name(hs.object_id) AS 'object name',
i.name as 'index name',
hs.total_bucket_count,
hs.empty_bucket_count,
floor((cast(empty_bucket_count as float)/total_bucket_count) * 100) AS 'empty_bucket_percent',
hs.avg_chain_length,
hs.max_chain_length
FROM sys.dm_db_xtp_hash_index_stats AS hs
JOIN sys.indexes AS i
ON hs.object_id=i.object_id AND hs.index_id=i.index_id
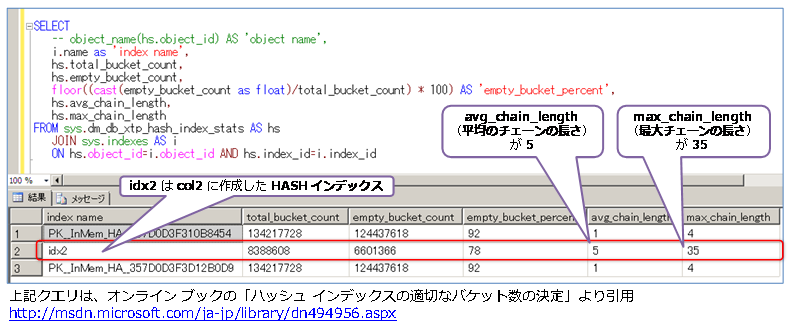
上の結果は、col2 列に作成した HASH インデックスの場合の結果ですが、col2 列は同じ値が約 5件なので、avg_chain_length(平均のチェーンの長さ)も 5 になっていることを確認できます。
col3 列に作成した HASH インデックス(idx3)の場合は、次のような結果になります。
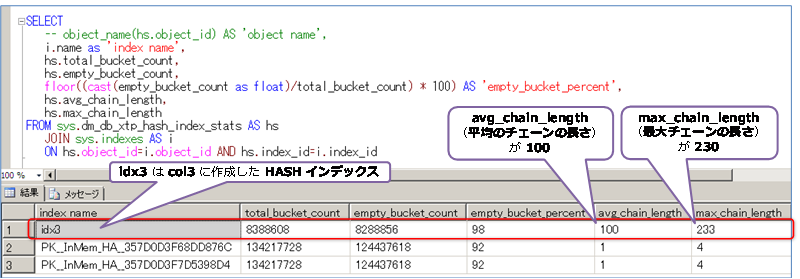
col3 列は同じ値が約 100件なので、avg_chain_length(平均のチェーンの長さ)も 100 になっていることを確認できます。


SQL Server 2016 の教科書(ソシム)



ASP.NET でいってみよう
第7刷 16,500 部発行
SQL Server 2000 でいってみよう
第12刷 28,500 部発行

SQL Server 2014 CTP2 インメモリ OLTP 機能の概要(Amazon Kindle 書籍)
(公開活動などのお知らせ)
第60回:SQL Server 2017 自習書 No.3「SQL Server 2017 Machine Learning Services」のご案内
第59回:SQL Server 2017 自習書 No.2「SQL Server 2017 on Linux」のご案内
第58回:SQL Server 2017 自習書 No.1「SQL Server 2017 新機能の概要」のご案内
第57回:SQL Server 2017 RC 版とこれまでのドキュメントのまとめ
第56回:「SQL Server 2016 への移行とアップグレードの実践」完成&公開!
第55回:書籍「SQL Server 2016の教科書 開発編」(ソシム)が発刊されました
第54回:「SQL Server 2016 プレビュー版 Reporting Services の新機能」自習書のお知らせ
第 53 回:SQL Server 2016 Reporting Services の新しくなったレポート マネージャーとモバイル レポート機能
第 52 回:SQL Server 2016 の自習書を作成しました!
第 51 回:PASS Summit と MVP Summit で進化を確信!
第 50 回:新しくなった Power BI(2.0)の自習書を作成しました!
第49 回:Excel 2016 の Power Query を使う
第 48 回:新しくなった Microsoft Power BI ! 無料版がある!!
第 47 回:「Microsoft Azure SQL Database 入門」 完成&公開!
第 46 回:Microsoft Power BI for Windows app からの Power BI サイト アクセス
第 45 回:Power Query で取得したデータを PowerPivot へ読み込む方法と PowerPivot for Excel 自習書のご紹介
第44回:「SQL Server 2014 への移行とアップグレードの実践」ドキュメントを作成しました
第43回:SQL Server 2014 インメモリ OLTP 機能の上級者向けドキュメントを作成しました
第42回:Power Query プレビュー版 と Power BI for Office 365 へのクエリ保存(共有クエリ)
第41回:「SQL Server 2014 CTP2 インメモリ OLTP 機能の概要」自習書のお知らせです
第40回: SQL Server 2012 自習書(HTML版)を掲載しました
第39回: Power BI for Office 365 プレビュー版は試されましたか?
第38回: SQL Server 2014 CTP2 の公開
第37回: SQL Server 2014 CTP1 の自習書をご覧ください
第36回: SQL Server 2014 CTP1 のクラスター化列ストア インデックスを試す
第35回: SQL Server 2014 CTP1 のインメモリ OLTP の基本操作を試す
第34回: GeoFlow for Excel 2013 のプレビュー版を試す
第33回: iPad と iPhone からの SQL Server 2012 Reporting Servicesのレポート閲覧
第32回: PASS Summit 2012 参加レポート
第31回: SQL Server 2012 Reporting Services 自習書のお知らせ
第30回: SQL Server 2012(RTM 版)の新機能 自習書をご覧ください
第29回: 書籍「SQL Server 2012の教科書 開発編」のお知らせ
第26回: SQL Server 2012 の Power View 機能のご紹介
第25回: SQL Server 2012 の Data Quality Services
第24回: SQL Server 2012 自習書のご案内と初セミナー報告
第23回: Denali CTP1 が公開されました
第22回 チューニングに王道あらず
第21回 Microsoft TechEd 2010 終了しました
第20回 Microsoft TechEd Japan 2010 今年も登壇します
第19回 SQL Server 2008 R2 RTM の 日本語版が公開されました
第18回 「SQL Azure 入門」自習書のご案内
第17回 SQL Server 2008 自習書の追加ドキュメントのお知らせ
第16回 SQL Server 2008 R2 自習書とプレビュー セミナーのお知らせ
第15回 SQL Server 2008 R2 Reporting Services と新刊のお知らせ
第14回 TechEd 2009 のご報告と SQL Server 2008 R2 について
第13回 SQL Server 2008 R2 の CTP 版が公開されました
第12回 MVP Summit 2009 in Seattle へ参加