
SQL Server 2014 実践シリーズ (HTML 版)
「No.1 インメモリ OLTP 機能の実践的な利用方法」
松本美穂と松本崇博が執筆した SQL Server 2014 実践シリーズの「No.1 インメモリ OLTP 機能の実践的な利用方法」の HTML 版です。 日本マイクロソフトさんの Web サイトで Word または PDF 形式でダウンロードできますが、今回、HTML 版として公開する許可をいただきましたので、ここに掲載いたします。[2015年12月29日]
2.12 char/varchar へ変更した場合の注意点
今回のポイントカード システムでは、もともとのテーブルのデータ型は char や varchar を利用していて、「カードID」や「カード種別」、「MessageID」、「企業コード」などは、英数字のデータしか格納されない(日本語は格納されない)ので、n付きの nchar や nvarchar(Unicode 対応のデータ型)へ変更する必要はなかったので、最初は、次のようなテーブル構成でテストを行っていました。

nchar/nvarchar(n付き)を利用した場合は、英数字データでも 2バイトを消費することになるので、データ量(メモリ使用量)が増えてしまって、遅くなるのではないか? という私の推測があって、最初に char/varchar を選択していました。
しかし、char/varchar を利用する上では、次のような大きな問題が 2つありました。
- データベースの照合順序が、Japanese_CI_AS だと、ネイティブ コンパイル SP のパラメーターのデータ型に char/varchar を利用することができない(パラメーターに nchar/nvarchar を利用した場合は、桁違いに遅くなってしまう)
- データベースの照合順序に、コード ページ 1252 の照合順序(例えば、英語版の既定値である SQL_Latin1_General_CP1_CI_AS など)を利用する場合は、日本語データがある場合に、N プレフィックスが必須になり、ADO.NETで SqlDbType.Char を利用している場合は、SqlDbType.NChar へ変更しなければいけなくなる(変更しないと性能が出ない)
データベースの照合順序に何を利用しているかによって、問題が変わってきますが、今回のシステムでは、既定の照合順序の Japanese_CI_AS を利用していました。この場合は、ネイティブ コンパイル SP のパラメーターのデータ型に char/varchar を利用することができないというのが大きなネックになりました。これは、前々項で紹介した以下のエラー メッセージです。
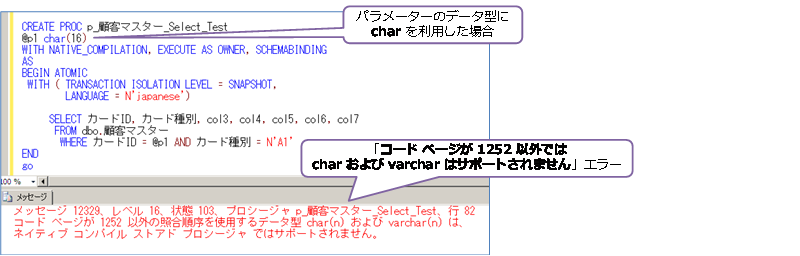
これを回避するには、パラメーターのデータ型に nchar/nvarchar を採用することですが、これを利用すると、検索処理で、桁違いに性能が低下するという大問題が発生してしまいました(後述)。
◆ データベースの照合順序に Japanese_CI_AS を利用している場合
データベースの照合順序に、Japanese_CI_AS を利用している場合は、char/varchar データ型にコード ページ 1252 以外の照合順序を利用することができないという制限もあります。これを回避するには、次のように Latin1_General_BIN2 など、1252コード ページの照合順序を使用するようにします。
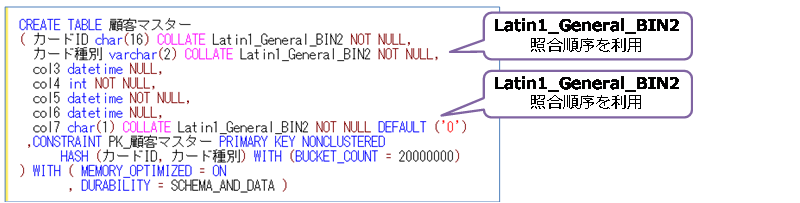
ただし、この 1252コード ページの照合順序では、日本語データを格納することができないので、日本語データを格納したい列には、nchar/nvarchar データ型を利用しなければなりません。また、一番の問題は、前述したように、ネイティブ コンパイル SP のパラメーターのデータ型に char/varchar を利用することができないことで、これでは性能が出ないことでした。
例えば、上記のように char で定義した顧客マスターに対して、検索を行う SELECT ステートメントを ネイティブ コンパイル SP 化すると次のようになります。

検索条件である「カードID」へ与えるパラメーターには、nchar(16) を利用しなければいけません。このように nchar(16) を利用した場合は、次のように実行プランが「Index Scan」(インデックスの全スキャン)になってしまい、桁違いに性能が悪くなります。
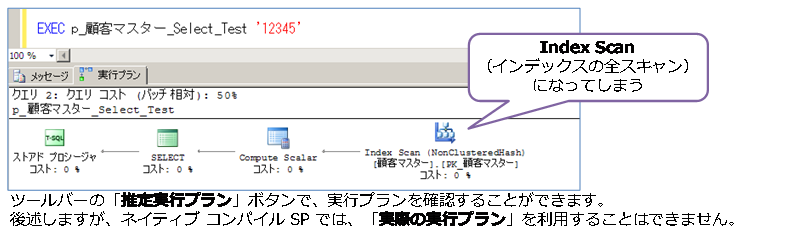
◆ 暗黙の型変換による大幅な性能低下 ~ char に対して nchar を利用するとき~
列のデータ型が char/varchar で、ネイティブ コンパイル SP のパラメーターのデータ型が nchar/nvarchar(n付き)の場合には、暗黙の型変換(Convert Implicit)が発生して、大幅な性能低下が発生します。前述の実行プランで確認したように、データ型が異なると、暗黙の型変換が発生して、Index Scan(インデックスの全スキャン)になってしまうからです。型が正しければ Index Seek(インデックスを利用したピンポイント検索)で済みます。
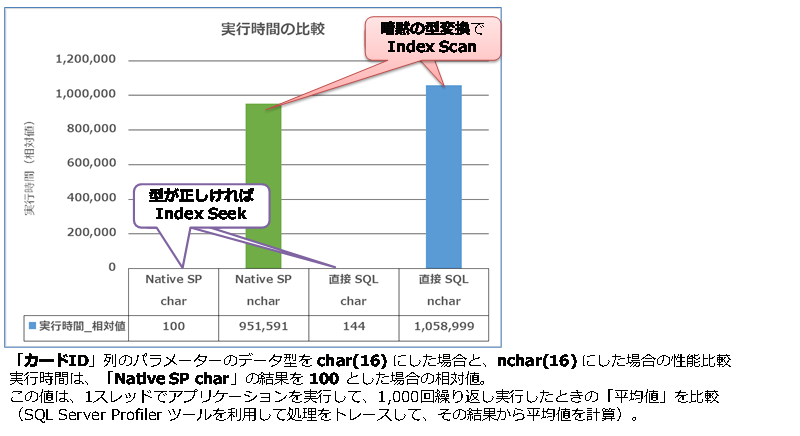
この場合の実行時間を比較すると、次のようになります。
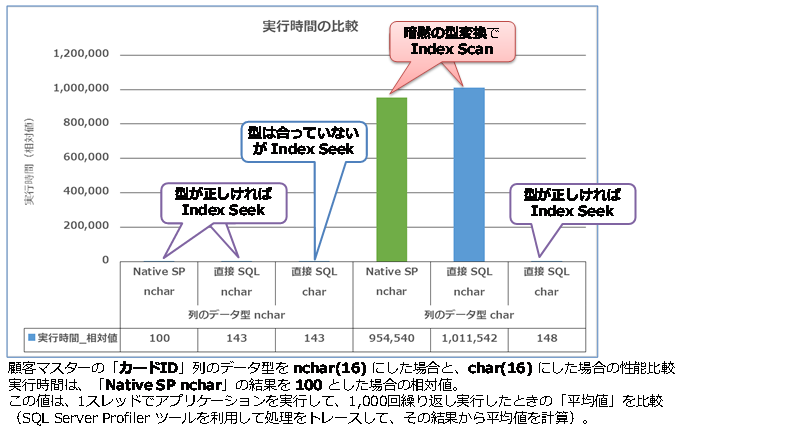
列のデータ型を nchar へ設定している場合は(グラフの左3つ)、型が正しければ、もちろん Index Seek で良い性能が出ますが、型が合わずに暗黙の型変換が発生した場合でも Index Seek になって、性能低下は発生しませんでした。
グラフ内の直接 SQL は、ネイティブ コンパイル SP を利用せずに、次のように ADO.NET から SQL を実行した場合です。
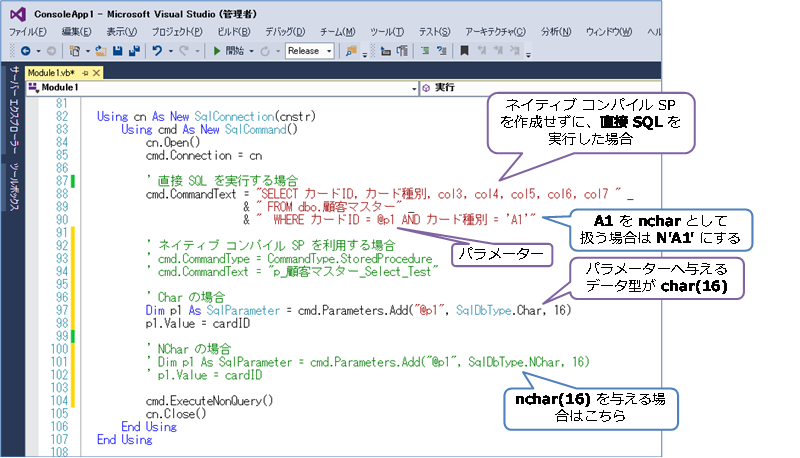
なお、このように、直接 SQL を実行した場合は、ネイティブ コンパイル SP を利用するよりも1.4倍程度遅くなります。
グラフの右3つは、列のデータ型を char へ設定している場合ですが、この場合は、ネイティブ コンパイル SP のパラメーターに char を利用することができないので、nchar を利用することで、暗黙の型変換が発生して、Index Scan(インデックスの全スキャン)になってしまっています。実行速度は、1万倍も遅い結果になりました(これは、仮に Index Seek が 10マイクロ秒で完了したとすると、Index Scan だと 100ミリ秒もかかってしまうという意味になります)。
列のデータ型を char へ設定している場合に、唯一、暗黙の型変換が発生しないのは、直接 SQL を実行するときで、次のように SqlParameter のデータ型に char を指定した場合のみです。
& " FROM dbo.顧客マスター" _
& " WHERE カードID = @p1 AND カード種別 = 'A1'"
Dim p1 As SqlParameter = cmd.Parameters.Add("@p1", SqlDbType.Char, 16)
このように型が合っていれば、Index Seek になってくれますが、直接 SQL を実行する方法は、ネイティブ コンパイル SP を利用するよりも、性能が劣るのが惜しいところです(1.4倍くらい低速)。
このように、データベースの照合順序に Japanese_CI_AS を利用して、列のデータ型を char にするのは難しいことが分かったので、次は、データベースの照合順序を Latin_~(コード ページ 1252)にすることを試してみました。
◆ データベースの照合順序に 1252 コード ページを利用する場合(Latin_~)
データベースの照合順序に、コード ページ 1252(例えば、英語版の既定値である SQL_Latin1 _General_CP1_CI_AS など)を利用した場合は、ネイティブ コンパイル SP のパラメーターのデータ型に char/varchar を利用することができます。
ただし、日本語データを格納したい場合には、nchar/nvarchar データ型へ変更しなければなりません(Japanese_CI_AS であれば、char/varchar でも日本語データを格納可能です)。また、日本語データを扱うときには、N プレフィックスも必須になり、ADO.NET で SqlParameter をSqlDbType.Char として利用している場合は、SqlDbType.NChar へ変更する必要もあります(後述しますが、変更しないと性能が出ません)。
データベースの照合順序は、次のようにデータベースを作成するときに指定することができます(データベース名を db1_Latin とする場合)。
ON PRIMARY ( NAME = db1_Latin_data,
FILENAME = 'D:\testDB\db1_Latin_data.mdf',
SIZE = 102400MB ),
FILEGROUP fg1 CONTAINS MEMORY_OPTIMIZED_DATA
( NAME = db1_Latin_InMem,
FILENAME = 'D:\testDB\db1_Latin_InMem' )
LOG ON
( NAME = db1_Latin_log,
FILENAME='D:\testDB\db1_Latin_log.ldf',
SIZE = 10240MB )
COLLATE SQL_Latin1_General_CP1_CI_AS
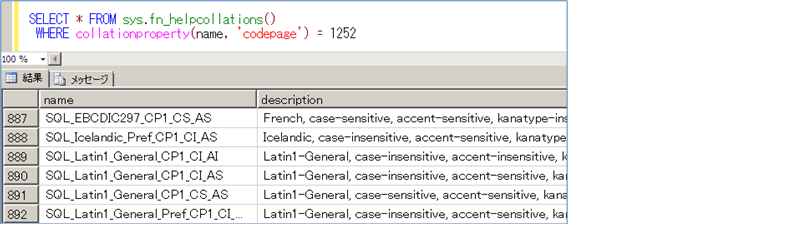
CREATE DATABASE ステートメントの末尾に、COLLATE 句を付けて、照合順序を指定することができます(COLLATE 句を省略した場合は、サーバーの照合順序に設定されます)。なお、コード ページ 1252 の照合順序の一覧は、次のように fn_helpcollations を利用して、取得することもできます。
WHERE collationproperty(name, 'codepage') = 1252
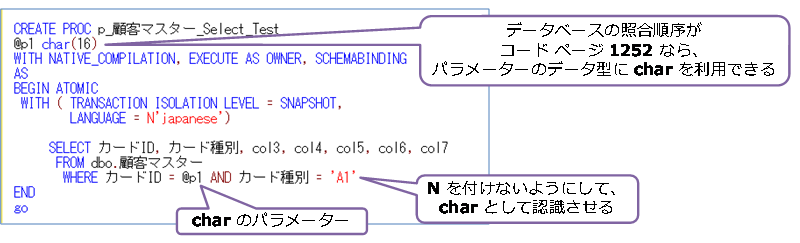
このように、データベースの照合順序を SQL_Latin1_General_CP1_CI_AS へ設定して、次のように「顧客マスター」テーブルを作成(カードID 列を char(16) へ設定)してテストを行いました。

ネイティブ コンパイル SP は、次のように char(16) のパラメーターで作成しました。
このように、列のデータ型と、パラメーターのデータ型が合っていれば(同じであれば)、次のように Index Seek で検索できるようになります。
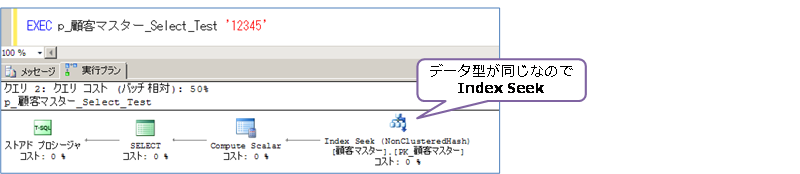
この場合の実行時間を比較すると、次のようになりました。
列のデータ型とパラメーターのデータ型が正しければ(同じであれば)、Index Seek で良い性能が出ますが、パラメーターに nchar を利用してしまうと、暗黙の型変換が発生して、Index Scan(インデックスの全スキャン)になってしまいます(1万倍遅い結果)。
Japanese_CI_AS のときは、直接 SQL を実行する方法でしか、データ型を合わせることができませんでしたが、コード ページ 1252 を利用している場合は、ネイティブ コンパイル SP のパラメーターに char/varchar を利用することができるので、(データ型さえ間違えなければ)性能面でのロスがなくなります。
実際に、今回のポイントカード システムでの各ステートメントをシングル実行したときの実行時間を計測すると、次のようになりました。

結果は、Japanese_CI_AS でも、Latin_~ でも、ほとんど差が出ませんでした。
テスト前は、私の経験上、char のほうが速くなるだろうと予想していたのですが、今回のテストでは、その差を感じることができませんでした。しかし、char/varchar データ型を利用することで、メモリ使用量を削減することができるので、このメリットは非常に大きく、今回は利用しませんでしたが、メモリ使用量を抑えたい場合に、非常に有用なオプションであると感じました(メモリ使用量については、後述します)。
◆ 暗黙の型変換のまとめ ~ char のときに nchar だと遅くなる~
暗黙の型変換について、いろいろなパターンを試しましたので、ここでまとめておきます。
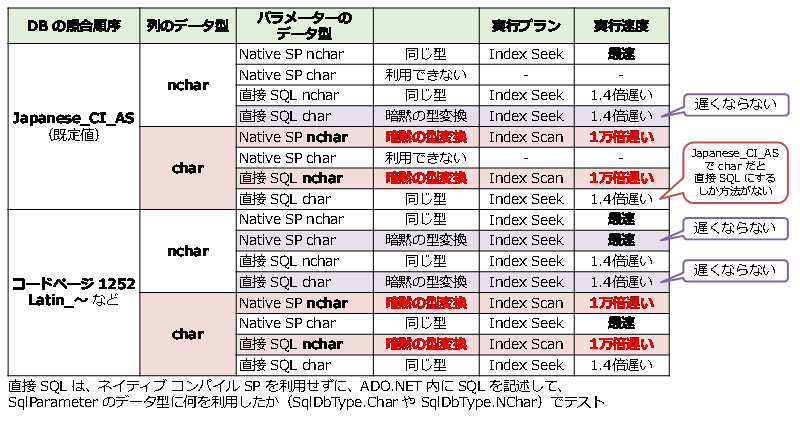
この表のポイントは、次のとおりです。
- 列のデータ型に nchar/nvarchar を利用している場合は、暗黙の型変換が発生しても、遅くはならない(Index Scan にはならず、Index Seek で検索してくれる)
- 列のデータ型に char/varchar を利用していて、ネイティブ コンパイル SP のパラメーターや、ADO.NET の SqlParameter で nchar/nvarchar を利用している場合は、暗黙の型変換が発生して、Index Scan になってしまい、1万倍遅くなる
- Japanese_CI_AS で、列のデータ型に char/varchar を利用している場合は、ネイティブ コンパイル SP のパラメーターに char/varchar を利用できないので、直接 SQL を実行する方法を利用せざるを得ない(他に回避策がない)
したがって、Japanese_CI_AS を利用している場合には、列のデータ型には、char/varchar を利用しないようにして、nchar/nvarchar を利用するように変更するのがお勧めになります。今回のポイントカード システムでは、char/varchar をすべて nchar/nvarchar へ変換しています。列のデータ型が nchar/nvarchar である場合は、パラメーターや SqlParameter で型を間違ったとしても、遅くはならないので、そのままアプリケーションを利用できる可能性が高くなります(実際、今回のポイントカード システムでの、ネイティブ コンパイル SP を利用しないテストでは、ADO.NET アプリケーションは修正せずに、SqlDbType.Char や SqlDbType.VarChar を利用したものでした)。
これに対して、列のデータ型に char/varchar を利用する場合は、パラメーターや SqlParameter で型を間違えると、桁違いに遅くなってしまうので、細心の注意が必要になります。このように遅くなってしまっては、せっかくインメモリ化しても、ディスク ベースよりも遅い結果になり、インメモリ OLTP の性能メリットを享受することができません。


SQL Server 2016 の教科書(ソシム)



ASP.NET でいってみよう
第7刷 16,500 部発行
SQL Server 2000 でいってみよう
第12刷 28,500 部発行

SQL Server 2014 CTP2 インメモリ OLTP 機能の概要(Amazon Kindle 書籍)
(公開活動などのお知らせ)
第60回:SQL Server 2017 自習書 No.3「SQL Server 2017 Machine Learning Services」のご案内
第59回:SQL Server 2017 自習書 No.2「SQL Server 2017 on Linux」のご案内
第58回:SQL Server 2017 自習書 No.1「SQL Server 2017 新機能の概要」のご案内
第57回:SQL Server 2017 RC 版とこれまでのドキュメントのまとめ
第56回:「SQL Server 2016 への移行とアップグレードの実践」完成&公開!
第55回:書籍「SQL Server 2016の教科書 開発編」(ソシム)が発刊されました
第54回:「SQL Server 2016 プレビュー版 Reporting Services の新機能」自習書のお知らせ
第 53 回:SQL Server 2016 Reporting Services の新しくなったレポート マネージャーとモバイル レポート機能
第 52 回:SQL Server 2016 の自習書を作成しました!
第 51 回:PASS Summit と MVP Summit で進化を確信!
第 50 回:新しくなった Power BI(2.0)の自習書を作成しました!
第49 回:Excel 2016 の Power Query を使う
第 48 回:新しくなった Microsoft Power BI ! 無料版がある!!
第 47 回:「Microsoft Azure SQL Database 入門」 完成&公開!
第 46 回:Microsoft Power BI for Windows app からの Power BI サイト アクセス
第 45 回:Power Query で取得したデータを PowerPivot へ読み込む方法と PowerPivot for Excel 自習書のご紹介
第44回:「SQL Server 2014 への移行とアップグレードの実践」ドキュメントを作成しました
第43回:SQL Server 2014 インメモリ OLTP 機能の上級者向けドキュメントを作成しました
第42回:Power Query プレビュー版 と Power BI for Office 365 へのクエリ保存(共有クエリ)
第41回:「SQL Server 2014 CTP2 インメモリ OLTP 機能の概要」自習書のお知らせです
第40回: SQL Server 2012 自習書(HTML版)を掲載しました
第39回: Power BI for Office 365 プレビュー版は試されましたか?
第38回: SQL Server 2014 CTP2 の公開
第37回: SQL Server 2014 CTP1 の自習書をご覧ください
第36回: SQL Server 2014 CTP1 のクラスター化列ストア インデックスを試す
第35回: SQL Server 2014 CTP1 のインメモリ OLTP の基本操作を試す
第34回: GeoFlow for Excel 2013 のプレビュー版を試す
第33回: iPad と iPhone からの SQL Server 2012 Reporting Servicesのレポート閲覧
第32回: PASS Summit 2012 参加レポート
第31回: SQL Server 2012 Reporting Services 自習書のお知らせ
第30回: SQL Server 2012(RTM 版)の新機能 自習書をご覧ください
第29回: 書籍「SQL Server 2012の教科書 開発編」のお知らせ
第26回: SQL Server 2012 の Power View 機能のご紹介
第25回: SQL Server 2012 の Data Quality Services
第24回: SQL Server 2012 自習書のご案内と初セミナー報告
第23回: Denali CTP1 が公開されました
第22回 チューニングに王道あらず
第21回 Microsoft TechEd 2010 終了しました
第20回 Microsoft TechEd Japan 2010 今年も登壇します
第19回 SQL Server 2008 R2 RTM の 日本語版が公開されました
第18回 「SQL Azure 入門」自習書のご案内
第17回 SQL Server 2008 自習書の追加ドキュメントのお知らせ
第16回 SQL Server 2008 R2 自習書とプレビュー セミナーのお知らせ
第15回 SQL Server 2008 R2 Reporting Services と新刊のお知らせ
第14回 TechEd 2009 のご報告と SQL Server 2008 R2 について
第13回 SQL Server 2008 R2 の CTP 版が公開されました
第12回 MVP Summit 2009 in Seattle へ参加