
SQL Server 2014 実践シリーズ (HTML 版)
「No.1 インメモリ OLTP 機能の実践的な利用方法」
松本美穂と松本崇博が執筆した SQL Server 2014 実践シリーズの「No.1 インメモリ OLTP 機能の実践的な利用方法」の HTML 版です。 日本マイクロソフトさんの Web サイトで Word または PDF 形式でダウンロードできますが、今回、HTML 版として公開する許可をいただきましたので、ここに掲載いたします。[2015年12月29日]
2.3 シングル実行時の性能(ネイティブ コンパイル SP で 1.74倍)
前の章では、シングル実行(多重実行ではなく、シングル スレッドでの単体実行)でも、性能が向上することを説明しました。
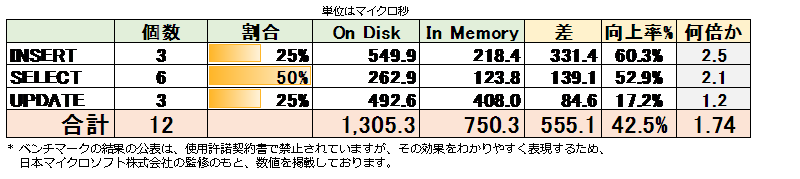
この値は、1スレッドでアプリケーションを実行して、過去のシステム利用状況をシミュレートして、1,000回の処理を実行したときの「平均値」を比較したものです(SQL Server Profiler ツールを利用して処理をトレース/キャプチャして、その結果から平均値を計算しています)。
全体として 1.74倍の性能向上(1.3ミリ秒から 750マイクロ秒へ向上)することを確認できました。また、INSERT ステートメント 3個では 2.5倍、SELECT ステートメント 6個では 2.1倍、UPDATE ステートメント 3個では 1.2倍の性能向上になりました。
このシングル実行での性能向上は、ネイティブ コンパイル SP を作成することで実現しています。
◆ ネイティブ コンパイル SP ではアプリケーションの修正が必要になる
ネイティブ コンパイル SP 化するにあたっては、ネイティブ コンパイル SP の作成と、それを利用するようにアプリケーションを修正する必要も出てきます。とは言っても、アプリケーションが .NET(VB + ADO.NET)で作られているのであれば、修正は簡単です。例えば、次のようなコードで SQL Server へアクセスしているとします。
Using cmd As New SqlCommand()
cn.Open()
cmd.Connection = cn
Dim sqlStr As String
sqlStr = "SELECT * FROM table1 WHERE col1 = @p1"
Dim p1 As SqlParameter = cmd.Parameters.Add("@p1", SqlDbType.Int)
p1.Value = 123
cmd.CommandText = sqlStr
End Using
End Using
このようにアプリケーションから実行している SELECT ステートメントを、次のようにネイティブ コンパイル SP 化したとします。
@p1 int
WITH NATIVE_COMPILATION, EXECUTE AS OWNER, SCHEMABINDING
AS
BEGIN ATOMIC
WITH ( TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'japanese' )
SELECT col1, col2, col3 FROM dbo.table1 WHERE col1 = @p1
END
このネイティブ コンパイル SP を利用するには、次のように SQL 文字列の部分(sqlStr 変数)を、ネイティブ コンパイル SP 名に変更して、SqlCommand オブジェクトのCommandType を「CommandType.StoredProcedure」へ変更するだけです。
cmd.Connection = cn
cmd.CommandType = CommandType.StoredProcedure ' この行を追加
Dim sqlStr As String
sqlStr = "p_table1_検索" ' この行をネイティブ コンパイル SP 名に変更
Dim p1 As SqlParameter = cmd.Parameters.Add("@p1", SqlDbType.Int)
:
このようにアプリケーションの修正は、簡単に行えますが、簡単とは言っても、修正後にきちんと動作するのかのテストなどが必要になるので、まずは、ネイティブ コンパイル SP を作成しないで、できる限りアプリケーションを修正することなく、インメモリ化するだけで、性能向上を実現できないか? と考え、テーブルだけを、メモリ最適化テーブルへ変更することを試みてみました。
◆ ネイティブ コンパイル SP を作成しないと効果がない??
ネイティブ コンパイル SP を作成しないで、各テーブルをメモリ最適化テーブルへ変更しただけの場合に、シングル実行したときの性能は、次のようになりました。

この方法は、アプリケーションを修正しなくても済むのが非常に大きなメリットで、各テーブルのインデックスを(メモリ最適化テーブルを利用するために)ハッシュ インデックスへ変更したり、ハッシュ インデックスを作成するために照合順序を Japanese_BIN2 へ変更したりするなどを行っていますが、今回対象となるテーブルが 6個のみであったこともあり、これらの変更は半日もあれば完了しました(具体的な作業方法については後述します)。
結果は、ディスク ベースのものと 14マイクロ秒しか差がでないものとなってしまいました(数値は、前項と同様、1スレッドで 1,000回の処理を実行したときの「平均値」を計算したもの)。
しかし、この結果は、あくまでもシングル実行(シングル スレッドでの単体実行)での結果です。本番を想定した 100多重での負荷テスト(1時間負荷をかけ続けるテスト)を実施すると、次のように 1.83倍の性能向上を確認することができました。
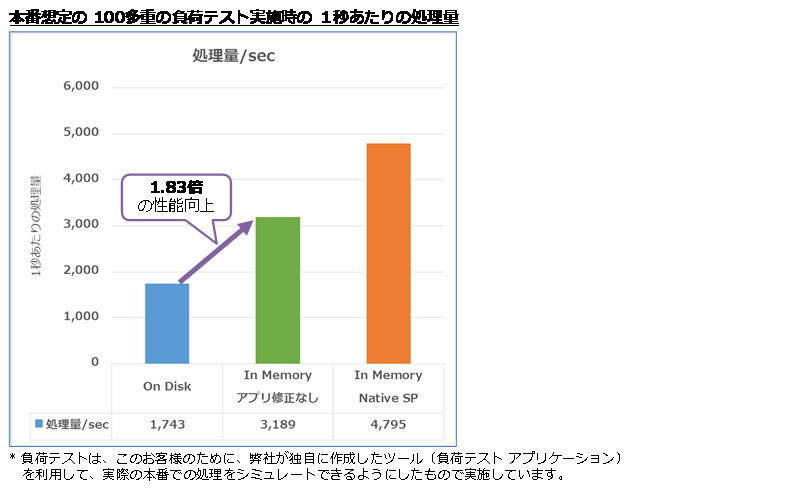

ディスク ベースでは、1秒あたり 1,743個の処理量であったところを、テーブルをメモリ最適化テーブルへ変更するだけで、1秒あたり 3,189個の処理ができるようになりました(1.83倍の性能向上)。
なんといっても、アプリケーションを修正することなく、テーブルを変更しただけで、1.83倍もの性能向上を実現できたことに驚きでした。従来ながらのディスク ベースのテーブルでは、多重度が上がったときに、ラッチ待ちやロック待ち、チェックポイント時のデータ ファイルへのフラッシュ、ログ書き込みの負荷、断片化の発生など、多くのオーバーヘッドがあるので、このような性能差を確認することができました。
◆ シングル実行も実は速くなるのでは?
上記のように多重実行で速くなることは確認できましたが、シングル実行でも、何かを変えれば速くなるのかもしれない、という期待があり、改めて、以下の表を見て、気が付くことがありました。

INSERT と UPDATE は若干速くなっていて、足を引っ張っているのは SELECT ステートメントなのではないかという疑問が沸いてきたので、SELECT ステートメントについて詳しく調べてみることにしました。
◆ 各 SELECT ステートメントの実行時間は?
シングル実行での足を引っ張っているのが SELECT ステートメントなのではないか、という疑問から、各ステートメントの実行時間を確認してみました。

すると、「顧客マスター」の SELECT ステートメントのみが倍近く遅い結果(58マイクロ秒が 93.8マイクロ秒)になっていて、そのほかは性能向上していることが分かりました。
◆ 遅かった SELECT ステートメント(IN 演算子を利用)
遅かった SELECT ステートメントは、次のような形をとっていました。
WHERE カードID = '12345'
AND カード種別 IN ('A1', 'A2', 'A3')
ORDER BY カード種別
この顧客マスターは、次のようなテーブル構成です(列名を伏せるために col3 や col4 など、実際の名前とは異なる名前へ変更しています)。
( カードID nchar(16) COLLATE Japanese_BIN2 NOT NULL,
カード種別 nvarchar(2) COLLATE Japanese_BIN2 NOT NULL,
col3 datetime NULL,
col4 int NOT NULL,
col5 datetime NOT NULL,
col6 datetime NULL,
col7 nchar(1) NOT NULL DEFAULT ('0')
,CONSTRAINT PK_顧客マスター PRIMARY KEY NONCLUSTERED
HASH (カードID, カード種別) WITH (BUCKET_COUNT = 20000000)
) WITH ( MEMORY_OPTIMIZED = ON
, DURABILITY = SCHEMA_AND_DATA )
(カードID, カード種別) を複合主キーとして PRIMARY KEY 制約に設定して、ハッシュ インデックスを作成しています。また、ハッシュ インデックスを作成するには、BIN2 の照合順序が必須になるので、Japanese_BIN2 を指定しています(メモリ最適化テーブルを作成するための要件については、第3章で説明します)。
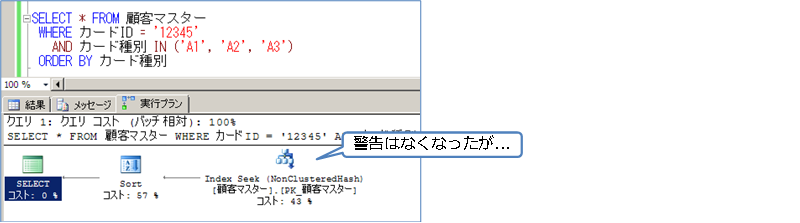
遅かった SELECT ステートメントの「実行プラン」を確認してみると、次のようになりました。
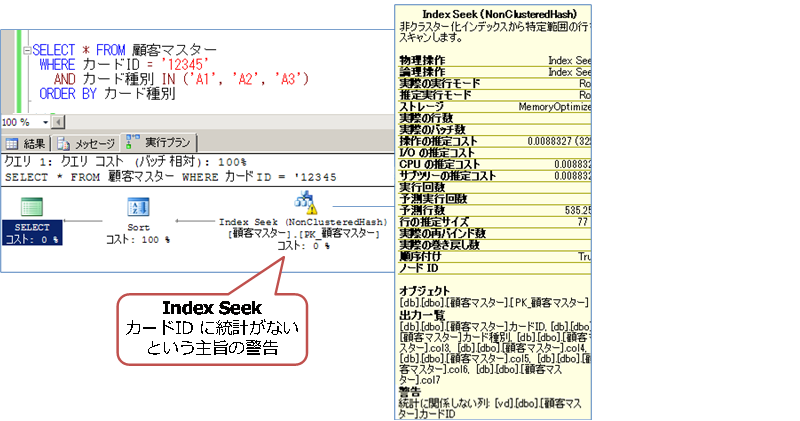
Index Seek(インデックスを利用したピンポイント検索)が選択されているので、実行プランを見る限りは問題がなさそうに見えます。黄色い警告が 1つ表示されていますが、これは、カードID 列に統計が作成されていないということで表示されています。
ディスク ベースのテーブルでは、複合インデックスの場合は、一番左に指定した列に対して、自動的に統計が作成されますが、メモリ最適化テーブルでは作成されないようです(2つ目の列のカード種別に対しては、クエリ実行後に自動作成されました)。
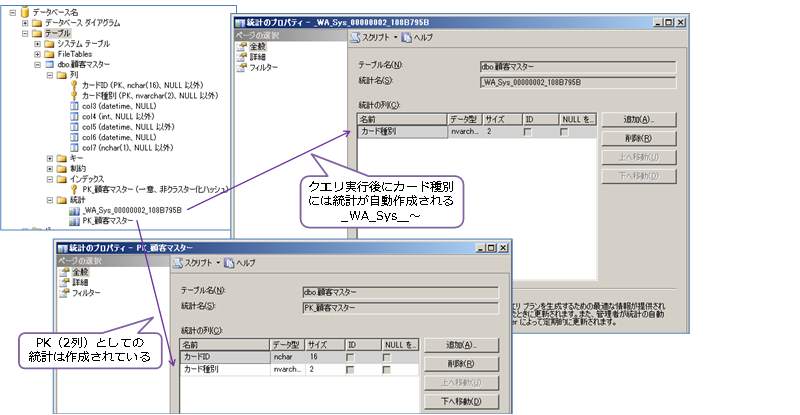
◆ 統計の作成 ~CREATE STATISTICS~
カードID 単体には、統計が作成されていないようだったので、CREATE STATISTICS ステートメントを利用して、次のように統計を作成してみました。
CREATE STATISTICS カードID_stats
ON 顧客マスター(カードID)
WITH FULLSCAN, NORECOMPUTE
このように統計を作成することによって、次のように実行プランに警告は表示されなくなりましたが、実行時間に変化はありませんでした(やはりディスク ベースの b-tree インデックスよりも遅い結果となりました)。
◆ クエリを分割して考えてみる ~ハッシュ インデックスの考え方~
統計を作成しても効果がなかったので、この問題を解決するために、クエリを分割して考えてみました。まず、「カードID」列のみで検索をしてみます。
WHERE カードID = '12345'
実行プランを確認してみると、次のように「Table Scan」になります。

私たちは、これを見たときに一瞬とまどってしまったのですが、b-tree インデックス的な発想だと、一番左の列に指定している列なら Index Seek になるわけです。しかし、Table Scan(全スキャン)になってしまっています。
これは、次のようにハッシュ インデックスをイメージすると分かりやすいと思います。
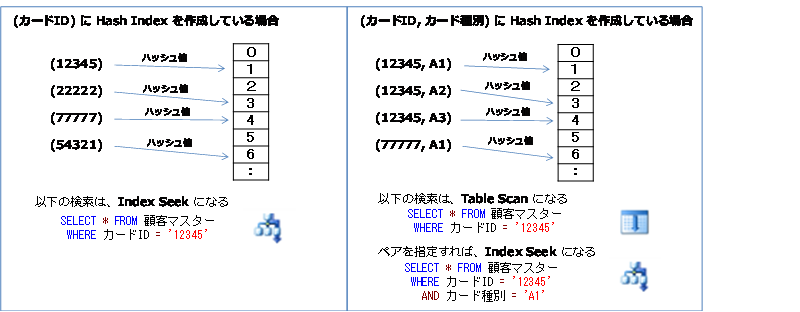
もし、「カードID」列にのみハッシュ インデックスを作成しているのであれば、左図のように Index Seek で検索できますが、(カードID, カード種別) のハッシュ インデックスでは、カードID とカード種別がペアになってハッシュ値を計算しているため、カードID の指定だけでは、インデックスを Seek(ピンポイント検索)できないのです(右図)。
これをヒントに、先ほどの遅かったクエリを改めてみてみます。
WHERE カードID = '12345'
AND カード種別 IN ('A1', 'A2', 'A3')
ORDER BY カード種別
カードID とカード種別を指定していて、実行プランも Index Seek でプラン的にも問題ない、統計を作成しても変わらない、そこで思い浮かんだのが、次の 2点です。
- IN 演算子が遅い?
- (カードID, カード種別) のペアがうまく認識されていない?
そこで、以下のように IN 演算子を利用しないで、カード種別を1つだけ指定した検索を行ってみました。
WHERE カードID = '12345'
AND カード種別 = 'A1'
ORDER BY カード種別
この検索は、ディスク ベースの検索と遜色ないスピード(むしろディスク ベースよりも少し速い?)という感触が得られました。ようやく希望が見えてきたので、次は、IN演算子を UNION ALL を使って分割してみました。
◆ IN 演算子を UNION ALL への変更
IN 演算子は、UNION で置換することができるので、次のクエリは、同じ結果を取得することができます。
SELECT * FROM table1
WHERE col1 IN ('A', 'B')
SELECT * FROM table1
WHERE col1 = 'A'
UNION
SELECT * FROM table1
WHERE col1 = 'B'
UNION は、重複データを除去する効果があるので、IN 演算子(OR)と等価になります。しかし、重複データを除去する部分は、余計なオーバーヘッドになるので、もし事前に重複データが発生することがあり得ないことが分かっているのであれば、UNION の代わりに UNION ALL を利用して、性能向上を計ることができます。今回のカードID とカード種別の関係は、まさにこの状況なので、UNION ALL が使える状況でした。
そこで、さきほどの SELECT ステートメントの IN演算子を、次のように UNION ALL を使って、分割してみました。
SELECT * FROM 顧客マスター
WHERE カードID = '12345' AND カード種別 = 'A1'
UNION ALL
SELECT * FROM 顧客マスター
WHERE カードID = '12345' AND カード種別 = 'A2'
UNION ALL
SELECT * FROM 顧客マスター
WHERE カードID = '12345' AND カード種別 = 'A3' ) t1
ORDER BY カード種別
この SELECT ステートメントは、同じカードID でカード種別が異なるもの(A1、A2、A3)を取得する、という検索なので、重複値が発生することはないので、UNION ALL を利用することができます。これを利用することで、次のようにディスク ベースよりも 28.9% の性能向上を実現することができました。

ここにたどり着くまでに丸々1日ぐらい費やしてしまいましたが、ハッシュ インデックスへの理解が深まったことは大きな収穫になりました。
この結果を、全体の結果へ当てはめてみると、次のように 5.1% の性能向上になりました。

UNION ALL を利用することで、アプリケーションの修正が必要になりましたが、インメモリ化しただけで、シングル実行でも性能向上を達成できたことは大きな驚きでした。
また、本番を想定した 100多重での負荷テストでは、次のように 1.93倍もの性能向上を確認することができました。
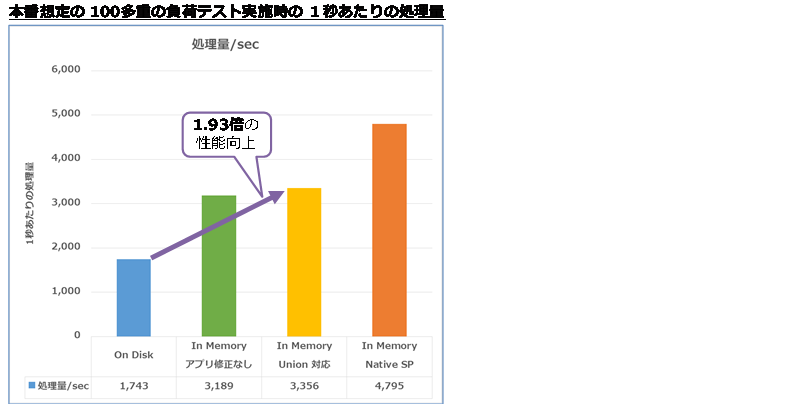
多重実行では、ラッチ待ちやロック待ち、チェックポイントの負荷などがかかるので、より大きな差になることを確認できました。なによりも、アプリケーションをほとんど修正することなく、1.93倍(2倍近い)の性能向上を実現できたことが驚きでした。
なお、ネイティブ コンパイル SP を作成すると、UNION ALL を利用するよりも、さらに速い実行時間で処理できていますが、ネイティブ コンパイル SP では IN 演算子や UNION ALL が利用できない、という制限があるところを、「メモリ最適化テーブル変数」を利用する、というテクニックを使っていますので、これについては後述します。
今回のシステムでは、IN 演算子で指定するカード種別が 3つと固定だったので、UNION ALL へ変更できましたが、もし IN で指定する値が可変の場合は、簡単に UNION へ変更することができません。このような場合は、後述する「bw-tree インデックス」を利用することで、今回のような問題へ対処することが可能です。


SQL Server 2016 の教科書(ソシム)



ASP.NET でいってみよう
第7刷 16,500 部発行
SQL Server 2000 でいってみよう
第12刷 28,500 部発行

SQL Server 2014 CTP2 インメモリ OLTP 機能の概要(Amazon Kindle 書籍)
(公開活動などのお知らせ)
第60回:SQL Server 2017 自習書 No.3「SQL Server 2017 Machine Learning Services」のご案内
第59回:SQL Server 2017 自習書 No.2「SQL Server 2017 on Linux」のご案内
第58回:SQL Server 2017 自習書 No.1「SQL Server 2017 新機能の概要」のご案内
第57回:SQL Server 2017 RC 版とこれまでのドキュメントのまとめ
第56回:「SQL Server 2016 への移行とアップグレードの実践」完成&公開!
第55回:書籍「SQL Server 2016の教科書 開発編」(ソシム)が発刊されました
第54回:「SQL Server 2016 プレビュー版 Reporting Services の新機能」自習書のお知らせ
第 53 回:SQL Server 2016 Reporting Services の新しくなったレポート マネージャーとモバイル レポート機能
第 52 回:SQL Server 2016 の自習書を作成しました!
第 51 回:PASS Summit と MVP Summit で進化を確信!
第 50 回:新しくなった Power BI(2.0)の自習書を作成しました!
第49 回:Excel 2016 の Power Query を使う
第 48 回:新しくなった Microsoft Power BI ! 無料版がある!!
第 47 回:「Microsoft Azure SQL Database 入門」 完成&公開!
第 46 回:Microsoft Power BI for Windows app からの Power BI サイト アクセス
第 45 回:Power Query で取得したデータを PowerPivot へ読み込む方法と PowerPivot for Excel 自習書のご紹介
第44回:「SQL Server 2014 への移行とアップグレードの実践」ドキュメントを作成しました
第43回:SQL Server 2014 インメモリ OLTP 機能の上級者向けドキュメントを作成しました
第42回:Power Query プレビュー版 と Power BI for Office 365 へのクエリ保存(共有クエリ)
第41回:「SQL Server 2014 CTP2 インメモリ OLTP 機能の概要」自習書のお知らせです
第40回: SQL Server 2012 自習書(HTML版)を掲載しました
第39回: Power BI for Office 365 プレビュー版は試されましたか?
第38回: SQL Server 2014 CTP2 の公開
第37回: SQL Server 2014 CTP1 の自習書をご覧ください
第36回: SQL Server 2014 CTP1 のクラスター化列ストア インデックスを試す
第35回: SQL Server 2014 CTP1 のインメモリ OLTP の基本操作を試す
第34回: GeoFlow for Excel 2013 のプレビュー版を試す
第33回: iPad と iPhone からの SQL Server 2012 Reporting Servicesのレポート閲覧
第32回: PASS Summit 2012 参加レポート
第31回: SQL Server 2012 Reporting Services 自習書のお知らせ
第30回: SQL Server 2012(RTM 版)の新機能 自習書をご覧ください
第29回: 書籍「SQL Server 2012の教科書 開発編」のお知らせ
第26回: SQL Server 2012 の Power View 機能のご紹介
第25回: SQL Server 2012 の Data Quality Services
第24回: SQL Server 2012 自習書のご案内と初セミナー報告
第23回: Denali CTP1 が公開されました
第22回 チューニングに王道あらず
第21回 Microsoft TechEd 2010 終了しました
第20回 Microsoft TechEd Japan 2010 今年も登壇します
第19回 SQL Server 2008 R2 RTM の 日本語版が公開されました
第18回 「SQL Azure 入門」自習書のご案内
第17回 SQL Server 2008 自習書の追加ドキュメントのお知らせ
第16回 SQL Server 2008 R2 自習書とプレビュー セミナーのお知らせ
第15回 SQL Server 2008 R2 Reporting Services と新刊のお知らせ
第14回 TechEd 2009 のご報告と SQL Server 2008 R2 について
第13回 SQL Server 2008 R2 の CTP 版が公開されました
第12回 MVP Summit 2009 in Seattle へ参加