
SQL Server 2014 実践シリーズ (HTML 版)
「No.1 インメモリ OLTP 機能の実践的な利用方法」
松本美穂と松本崇博が執筆した SQL Server 2014 実践シリーズの「No.1 インメモリ OLTP 機能の実践的な利用方法」の HTML 版です。 日本マイクロソフトさんの Web サイトで Word または PDF 形式でダウンロードできますが、今回、HTML 版として公開する許可をいただきましたので、ここに掲載いたします。[2015年12月29日]
4.8 フル スキャンを避ける(インメモリ OLTP の苦手な処理)
ここまでは、インメモリ OLTP が得意な処理に関して見てきましたが、もちろん苦手な処理もあります。それはフル スキャン(全スキャン)が発生するような場合です。これは、前項の範囲検索のところでも少し出ていますが、HASH インデックスを利用している場合に、範囲検索を行ったとすると、Index Seek にはならず、Table Scan または Index Scan が行われてしまい、桁違いに遅くなってしまう(前項ではネイティブ コンパイル SP 利用時に 82倍、直接 SQL を実行した場合に 172倍も遅くなってしまう)というものです。このスピードは、ディスク ベースでのフル スキャンよりも遅いものなので、注意しなければなりません。
◆ インメモリ OLTP のフル スキャンのスピード
ここでは、col2 の検索(取得件数が約 5件になる検証)で利用したのと同じテーブル(1,000万件のデータ)で説明します(以下)。
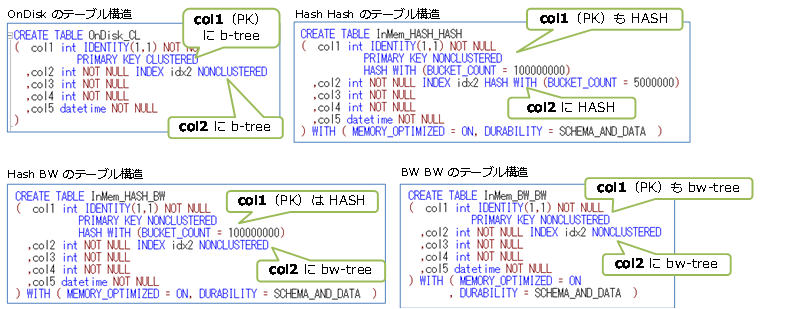
前述のテストでは、col2 列へインデックスを作成している場合は、「WHERE col2 = ~」のように「=」演算子を利用した検索は、次のように Index Seek になることを説明しました。
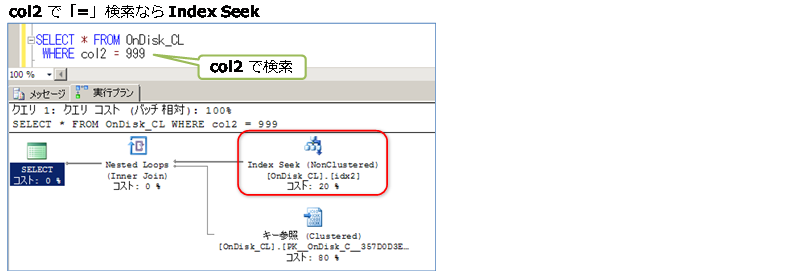
また、この検索は、ディスク ベースよりも、インメモリ OLTP のほうが速く結果を取得できることも確認しました(約1.3倍速い)。
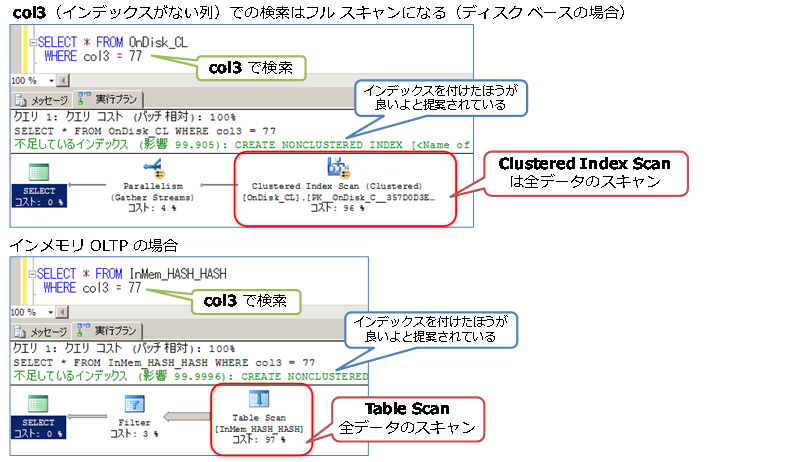
これに対して、「WHERE col3 = ~」のように、インデックスを作成していない列(col3)を利用した場合の検索は、次のようにフル スキャン(Table Scan または Index Scan)になります。
このように、フル スキャンになる検索を、次のように SET STATISTICS TIME コマンドを利用して実行時間を計測してみます。

結果は、次のようになりました。
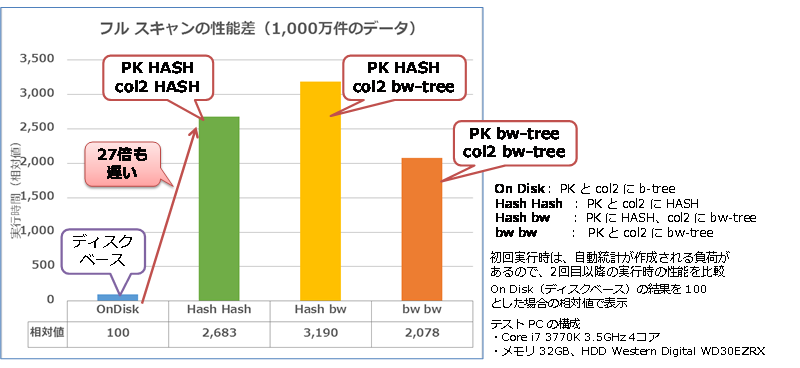

結果は、ディスク ベースでの全スキャンに比べて、HASH インデックスでも bw-tree インデックスでも桁違いに遅くなることが分かりました(強いて言えば、bw-tree インデックスが速いのですが....)。Hash Hash の 27倍遅いというのは、仮にディスク ベースが 100ミリ秒で完了したとすると、Hash Hash では 2.7秒もかかってしまうという意味で、この差は非常に大きいものです。
◆ ネイティブ コンパイル SP を作成するとフル スキャンにも効果がある
次に、ネイティブ コンパイル SP を作成した場合の性能差を確認してみました。

この場合の結果は、次のようになりました。
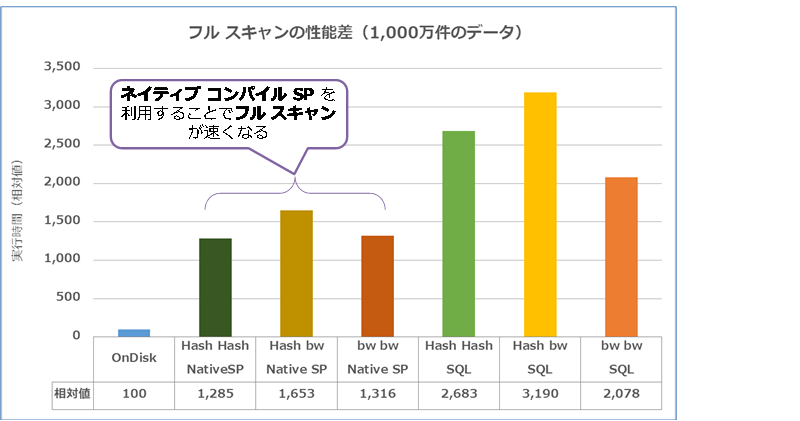
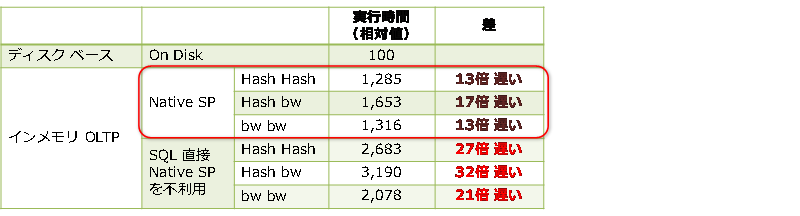
結果は、どのパターンも、直接 SQL を実行するよりも、ネイティブ コンパイル SP を利用したほうが速く実行できることを確認できました(Hash Hash は 27倍遅かったところが 13倍、bw bw は 21倍遅かったところが 13倍へ改善)。
このように、ネイティブ コンパイル SP を作成すれば、フル スキャンの性能を上げることができますが、これでもディスク ベースよりも 10倍以上遅い(仮にディスク ベースが 100ミリ秒なら、インメモリ OLTP では 1秒かかってしまう)ことに気を付けなければいけません(インメモリ OLTP は、フル スキャンが苦手です)。
したがって、インメモリ OLTP を利用する場合には、フル スキャン(全スキャン)にならないように、検索で利用する列に対して、インデックス(HASH または bw-tree)を確実に作成/付与しておくことが非常に重要になります。また、範囲スキャンを避けるには、bw-tree インデックスを活用することもポイントになります。
ディスク ベースでのフル スキャンが速い理由の 1つには、パラレル処理があります。これは、次のような状況です。
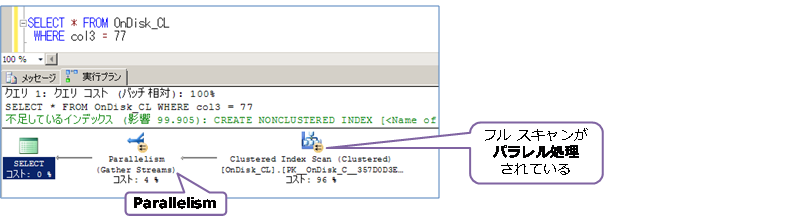
パラレル処理されているかどうかは、実行プランの黄色いアイコン( ← が2つあるもの)で確認することができます。これで、仮に CPU 時間が 400ミリ秒かかるような処理の場合に、4コアの CPU であれば 100~200ミリ秒ぐらい(∵ 4コア=4倍の性能にはならないため)で実行できるようになります。
◆ インメモリ OLTP は全データを対象とした処理が苦手 ~集計処理など~
前述したように、インメモリ OLTP では、フル スキャン(全スキャン)が遅いので、全データを対象とした集計処理も苦手です。これは、次のようなクエリです。
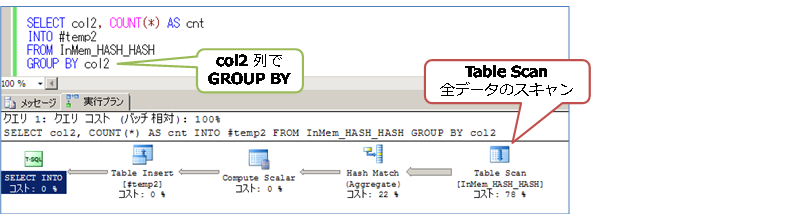
このクエリは、WHERE 句での絞り込みを行わないで、全データ(1,000万件)を対象としています。このような集計処理は、col2 列に HASH インデックスを作成していても、Table Scan(全スキャン)になってしまいます。
この処理を性能比較すると、次のようになります。
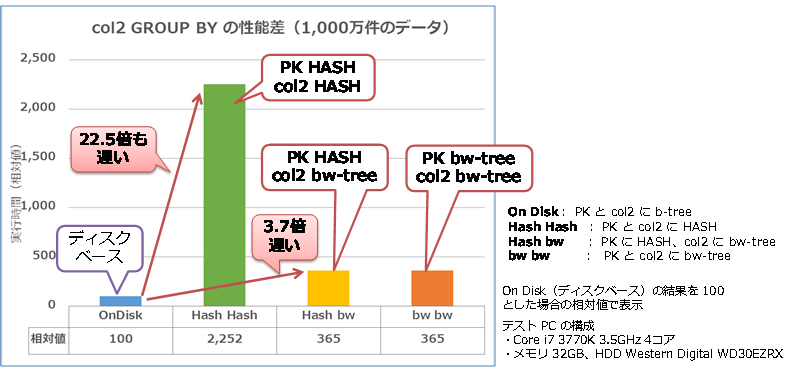

col2 列に HASH インデックスを作成している場合は 22.5倍も遅くなり、bw-tree インデックスを作成している場合は 3.6~3.7倍遅くなることを確認できました。これは、仮にディスク ベースでの結果が 500ミリ秒だったとすると、22.5倍では 13.5秒、3.6倍では 1.8秒もかかってしまうということを意味しています。
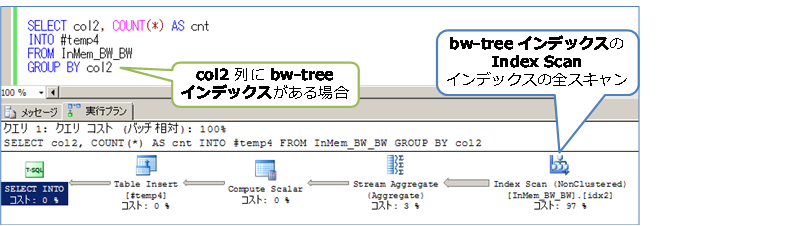
bw-tree インデックスのほうが性能が良い理由は、Table Scan ではなく、次のように Index Scan で行われているためです。
しかし、bw-tree インデックスのほうが性能が良いとは言っても(HASH インデックスの場合の 22.5倍に比べれば断然速いですが)、ディスク ベースと比べると約 3.6倍も遅いわけです。したがって、このような全データを対象とした集計処理を頻繁に行っている場合には、注意してください。
◆ col3 列(インデックスを付与していない列)で GROUP BY を行った場合
col2 列ではなく、col3 列(インデックスを作成していない列)で、GROUP BY 演算を行った場合は、次のような性能結果になります。
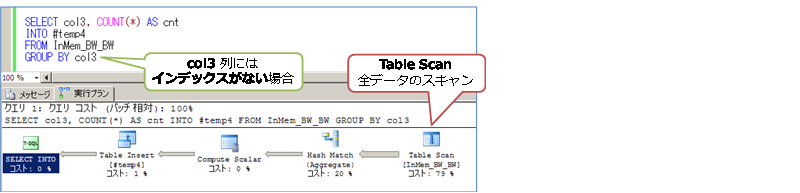
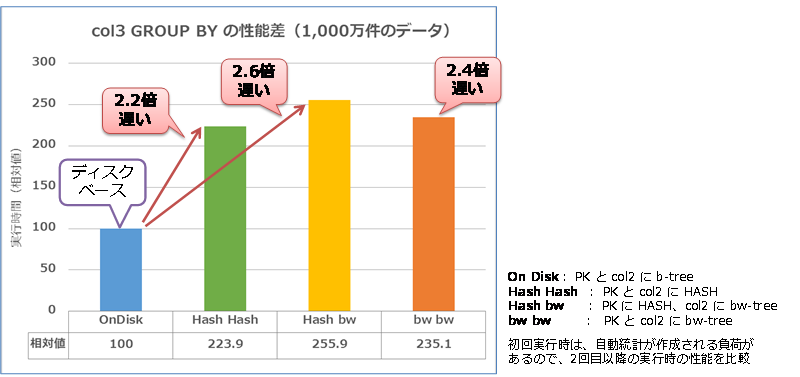
col3 での GROUP BY の場合は、ディスク ベースでも、インメモリ OLTP でも、どのパターンでも Table Scan になりますが(正確には、ディスク ベースでは Clustered Index Scan)、やはりディスク ベースよりも 2倍以上も遅い結果となりました。差が小さくなったのは、col2 列の GROUP BY の結果が 200万件であったのに対して、col3 では 10万件であったためです。
col3 のようにインデックスを付与していない列を GROUP BY 句や WHERE 句の検索条件に指定すると、初回実行時に自動的に統計が作成されるので(_WA_Sys_~という名前)、初回実行が遅くなります(統計の作成処理の負荷もインメモリ OLTP のほうが遅くなります)。
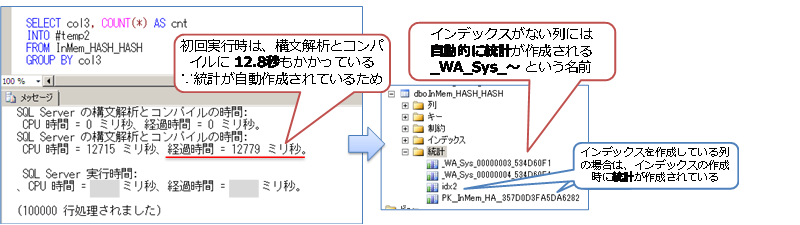
◆ col4 列(インデックスを付与していない列)で GROUP BY を行った場合
次に、col3 と同様、インデックスを作成していない col4 列で GROUP BY 演算を行ってみます。この場合は 1,000件の結果が返ります。
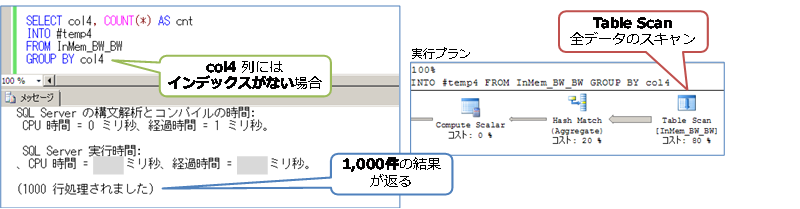
この場合の性能結果は、次のとおりです。
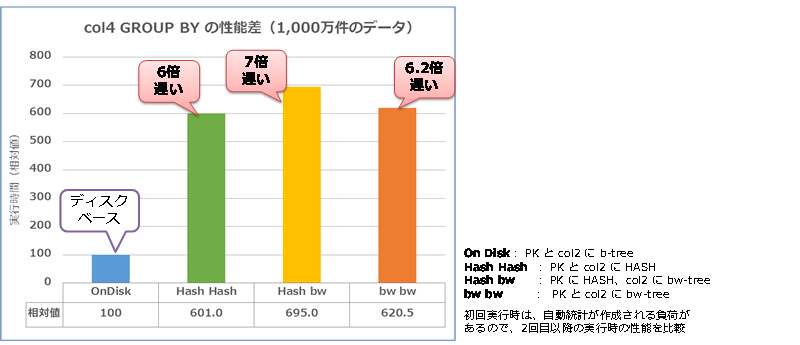
インメモリ OLTP の結果は、いずれもディスク ベースよりも 6倍以上遅い結果となりました。
col2、col3、col4 の結果を同じスケールにしてまとめると、次のようになります。
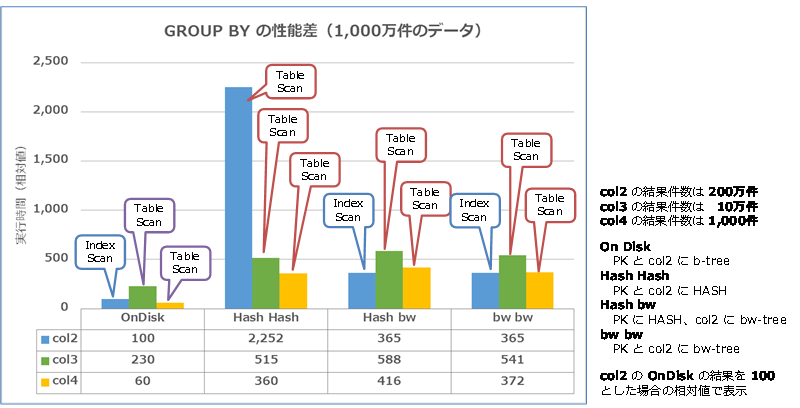
Index Scan でも Table Scan でも、インメモリ OLTP のほうがディスク ベースよりも遅いことを確認できると思います。なお、このテストでは、GROUP BY の結果を一時テーブルへ書き込んでいますが、ディスク ベースの場合は、次のようにパラレル処理(Parallel Insert)が可能で、その分の性能差も現れています。

◆ フル スキャンにはクラスター化列ストア インデックス(CCSI)を利用
インメモリ OLTP は、フル スキャンが苦手ですが、SQL Server 2014 には、フル スキャンが得意な機能として「クラスター化列ストア インデックス」(CCSI:Clustered Column-store Index)もあります。これは、カラム型データベース(列指向データベース)の SQL Server 実装で、SQL Server 2014 からの新機能です(SQL Server 2012 でも、非クラスター化列ストア インデックス機能を利用することで、読み取り専用で利用することもできます)。
クラスター化列ストア インデックスは、次のように作成することができます。
ON テーブル名

CREATE CLUSTERED COLUMNSTORE INDEX ステートメントで、インデックス名(画面は idx1)を指定し、ON 句でテーブル名(画面は CCSI_table)を指定すれば、作成が完了です。このようにクラスター化列ストア インデックスを作成すると、集計処理のパフォーマンスが大幅に向上します。
クラスター化列ストア インデックスを利用して、col2、col3、col4 の GROUP BY演算(1,000万件のデータ)を行った結果は、次のようになります。
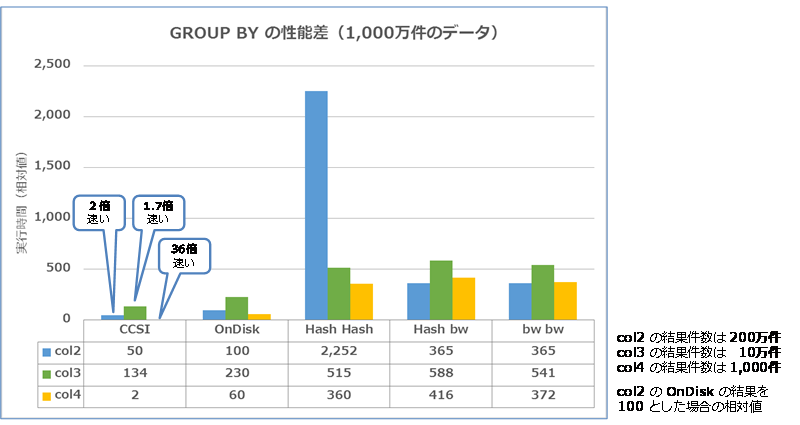
col2 列の集計処理では 2倍、col3 列では 1.7倍、col4 列では 36倍も速い結果になっています(col4 が桁違いに速いのは、結果件数が 1,000件と少ないためです)。このように、クラスター化列ストア インデックスを利用すれば、圧倒的な集計パフォーマンスを実現することができるので、集計処理が中心のシステムの場合には、検討してみることをお勧めします(インメモリ OLTP とクラスター化列ストア インデックスは、同じテーブルに対して設定することはできないので、集計処理を強くしたい場合にはクラスター化列ストア インデックスがお勧めになります)。
クラスター化列ストア インデックスについては、本実践シリーズの「SQL Server 2014 への移行/アップグレード」編でも詳しく説明するので、こちらもぜひご覧いただければと思います。


SQL Server 2016 の教科書(ソシム)



ASP.NET でいってみよう
第7刷 16,500 部発行
SQL Server 2000 でいってみよう
第12刷 28,500 部発行

SQL Server 2014 CTP2 インメモリ OLTP 機能の概要(Amazon Kindle 書籍)
(公開活動などのお知らせ)
第60回:SQL Server 2017 自習書 No.3「SQL Server 2017 Machine Learning Services」のご案内
第59回:SQL Server 2017 自習書 No.2「SQL Server 2017 on Linux」のご案内
第58回:SQL Server 2017 自習書 No.1「SQL Server 2017 新機能の概要」のご案内
第57回:SQL Server 2017 RC 版とこれまでのドキュメントのまとめ
第56回:「SQL Server 2016 への移行とアップグレードの実践」完成&公開!
第55回:書籍「SQL Server 2016の教科書 開発編」(ソシム)が発刊されました
第54回:「SQL Server 2016 プレビュー版 Reporting Services の新機能」自習書のお知らせ
第 53 回:SQL Server 2016 Reporting Services の新しくなったレポート マネージャーとモバイル レポート機能
第 52 回:SQL Server 2016 の自習書を作成しました!
第 51 回:PASS Summit と MVP Summit で進化を確信!
第 50 回:新しくなった Power BI(2.0)の自習書を作成しました!
第49 回:Excel 2016 の Power Query を使う
第 48 回:新しくなった Microsoft Power BI ! 無料版がある!!
第 47 回:「Microsoft Azure SQL Database 入門」 完成&公開!
第 46 回:Microsoft Power BI for Windows app からの Power BI サイト アクセス
第 45 回:Power Query で取得したデータを PowerPivot へ読み込む方法と PowerPivot for Excel 自習書のご紹介
第44回:「SQL Server 2014 への移行とアップグレードの実践」ドキュメントを作成しました
第43回:SQL Server 2014 インメモリ OLTP 機能の上級者向けドキュメントを作成しました
第42回:Power Query プレビュー版 と Power BI for Office 365 へのクエリ保存(共有クエリ)
第41回:「SQL Server 2014 CTP2 インメモリ OLTP 機能の概要」自習書のお知らせです
第40回: SQL Server 2012 自習書(HTML版)を掲載しました
第39回: Power BI for Office 365 プレビュー版は試されましたか?
第38回: SQL Server 2014 CTP2 の公開
第37回: SQL Server 2014 CTP1 の自習書をご覧ください
第36回: SQL Server 2014 CTP1 のクラスター化列ストア インデックスを試す
第35回: SQL Server 2014 CTP1 のインメモリ OLTP の基本操作を試す
第34回: GeoFlow for Excel 2013 のプレビュー版を試す
第33回: iPad と iPhone からの SQL Server 2012 Reporting Servicesのレポート閲覧
第32回: PASS Summit 2012 参加レポート
第31回: SQL Server 2012 Reporting Services 自習書のお知らせ
第30回: SQL Server 2012(RTM 版)の新機能 自習書をご覧ください
第29回: 書籍「SQL Server 2012の教科書 開発編」のお知らせ
第26回: SQL Server 2012 の Power View 機能のご紹介
第25回: SQL Server 2012 の Data Quality Services
第24回: SQL Server 2012 自習書のご案内と初セミナー報告
第23回: Denali CTP1 が公開されました
第22回 チューニングに王道あらず
第21回 Microsoft TechEd 2010 終了しました
第20回 Microsoft TechEd Japan 2010 今年も登壇します
第19回 SQL Server 2008 R2 RTM の 日本語版が公開されました
第18回 「SQL Azure 入門」自習書のご案内
第17回 SQL Server 2008 自習書の追加ドキュメントのお知らせ
第16回 SQL Server 2008 R2 自習書とプレビュー セミナーのお知らせ
第15回 SQL Server 2008 R2 Reporting Services と新刊のお知らせ
第14回 TechEd 2009 のご報告と SQL Server 2008 R2 について
第13回 SQL Server 2008 R2 の CTP 版が公開されました
第12回 MVP Summit 2009 in Seattle へ参加