
SQL Server 2014 実践シリーズ (HTML 版)
「No.1 インメモリ OLTP 機能の実践的な利用方法」
松本美穂と松本崇博が執筆した SQL Server 2014 実践シリーズの「No.1 インメモリ OLTP 機能の実践的な利用方法」の HTML 版です。 日本マイクロソフトさんの Web サイトで Word または PDF 形式でダウンロードできますが、今回、HTML 版として公開する許可をいただきましたので、ここに掲載いたします。[2015年12月29日]
3.4 メモリ最適化テーブルへ移行する手順
データベースの設定が完了した後は、既存のディスク ベースのテーブルを、メモリ最適化テーブルへ移行する作業になります。
メモリ最適化テーブルへ移行する手順の概要は、次のとおりです。
- 既存のテーブルの名前を変更する(sp_rename を利用)
- 既存のテーブルをスクリプト化する(CREATE TABLE ステートメントを自動生成可能)
- インデックスを作成する列には、NOT NULL が必須になるので、NOT NULL を付与する
- データベースの照合順序に Japanese_CI_AS(日本語版の SQL Server の場合の既定値)を利用している場合は、char/varchar データ型を nchar/nvarchar データ型へ変換する(詳しくは 2.12を参照)
- PRIMARY KEY 制約のインデックスを、ハッシュ インデックスまたは bw-tree インデックスへ変更する
- PRIMARY KEY 制約を設定する列が char 系のデータ型の場合には、BIN2 照合順序(Japanese_BIN2 や Latin1_General_BIN2 など)へ変更する
- ハッシュ インデックスのバケット数(BUCKET_COUNT)を決定する(バケット数の決定基準については、第4章で説明)
- PRIMARY KEY 以外にインデックスを作成している場合は、既存のインデックスを右クリックして、スクリプト化する(CREATE INDEX ステートメントを自動生成可能)
- インデックスのスクリプトをもとに、ハッシュ インデックスまたは bw-tree インデックスへ変更して、CREATE TABLE ステートメントの列定義へ追加する
- メモリ最適化テーブルを作成するための CREATE TABLE ステートメントを実行する
- データを既存のテーブルからメモリ最適化テーブルへコピーする(INSERT .. SELECT を利用して、全データをコピーする)
- ネイティブ コンパイル SP を作成する(オプション)
◆ 既存のテーブルの名前を変更(sp_rename を利用)
まずは、既存のディスク ベースのテーブルを sp_rename システム ストアド プロシージャを利用して、名前を変更しておきます。「顧客マスター」テーブルの場合は、次のように名前を変更できます。
EXEC sp_rename '顧客マスター', '顧客マスター_OnDisk'

sp_rename では、第1引数に名前を変更したいテーブル、第2引数に変更後の名前を指定するので、この例では「顧客マスター」を「顧客マスター_OnDisk」という名前へ変更できます。
◆ 既存のテーブルをスクリプト化(CREATE TABLE を自動生成)
次に、既存のディスク ベースのテーブルをスクリプト化します(CREATE TABLE ステートメントを自動生成します)。こを行うには、次のようにオブジェクト エクスプローラーで、該当テーブルを右クリックして、[テーブルをスクリプト化]から[新規作成]の[新しいクエリ エディター ウィンドウ]をクリックします。
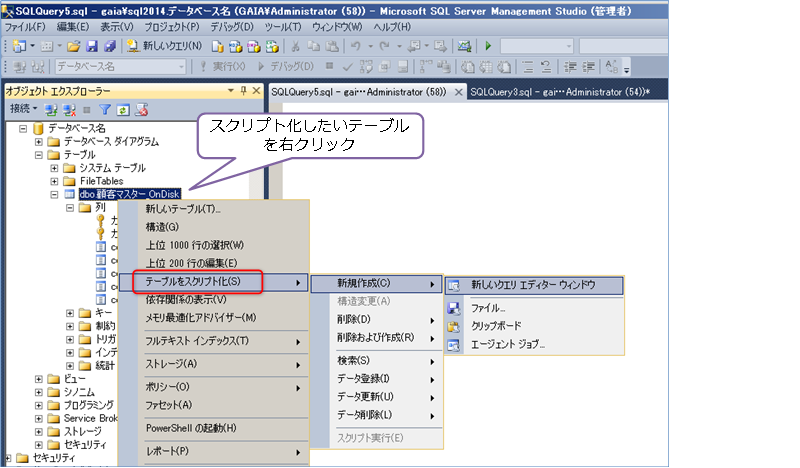
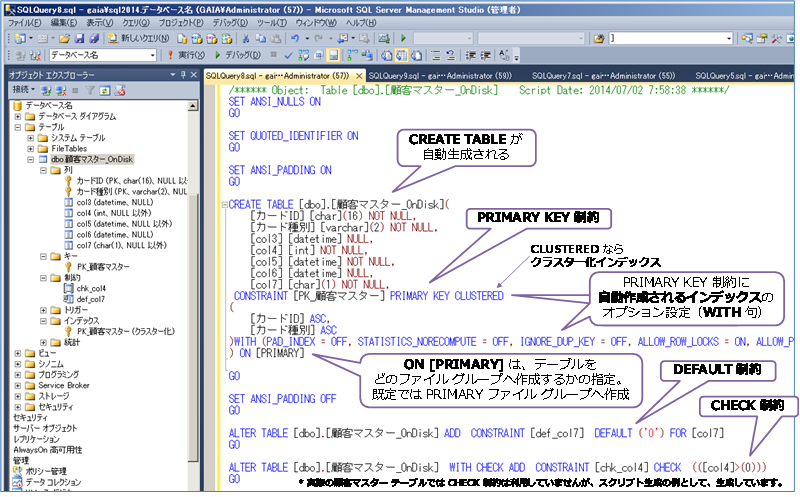
CREATE TABLE ステートメントが生成されて、PRIMARY KEY 制約や、PRIMARY KEY 制約に自動作成されるインデックス(既定ではクラスター化インデックス)、各種制約(DEFAULT 制約や CHECK 制約など)がスクリプト化されることを確認できます。
このスクリプトをもとに、メモリ最適化テーブルを作成するための CREATE TABLE ステートメントへ修正していきます。
既存のテーブルで、列ごとに異なる照合順序を設定している場合には、スクリプトを生成するときに、照合順序も一緒に生成する必要があります。これを行うには、スクリプト生成ウィザードを利用します。このウィザードを起動するには、次のように該当データベースを右クリックして、[タスク]メニュー[スクリプト生成]をクリックします。
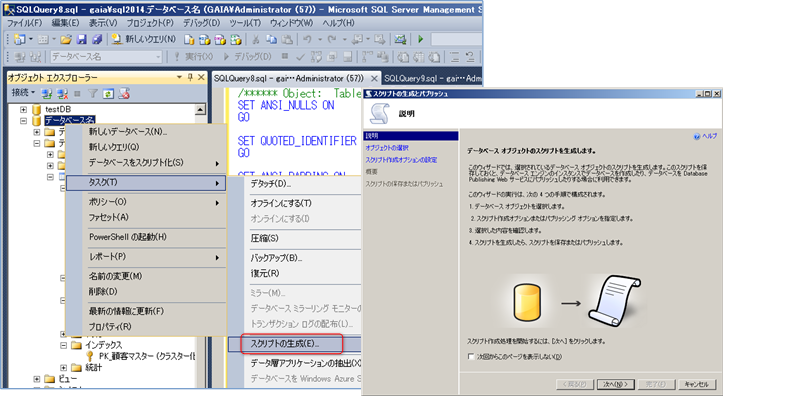
ウィザードの[オブジェクトの選択]ページでは、スクリプト化をしたいテーブルを選択します。
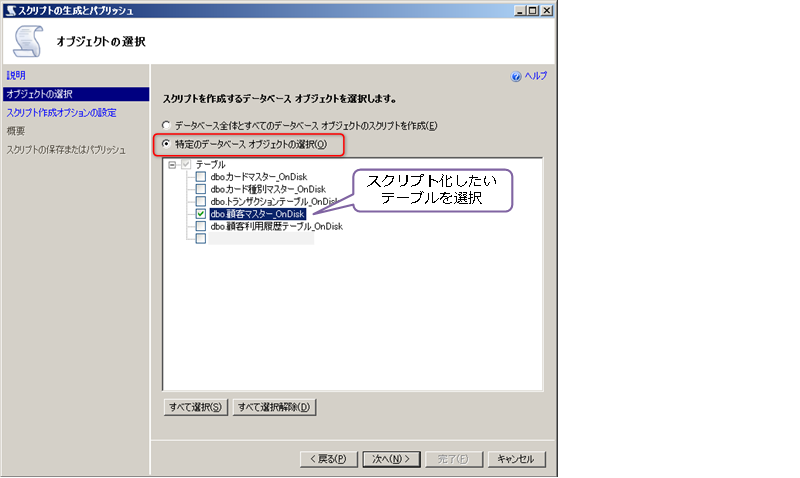
次の[スクリプト作成オプションの設定]ページでは、[詳細設定]ボタンをクリックします。
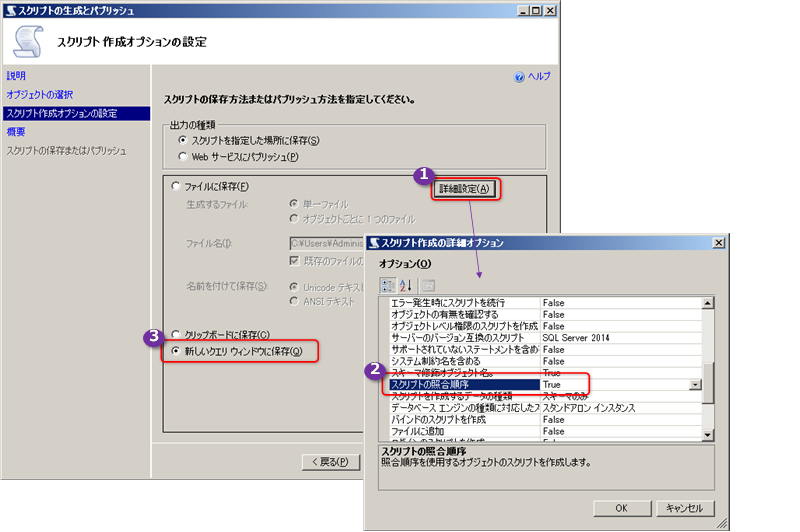
[詳細オプション]ダイアログが表示されたら、[スクリプトの照合順序]を「True」へ変更することで、照合順序の付きのスクリプトを生成できるようになります。あとは、[新しいクエリ エディター ウィンドウに保存]をクリックしておけば、次のようにクエリ エディターへスクリプトを生成することができます。
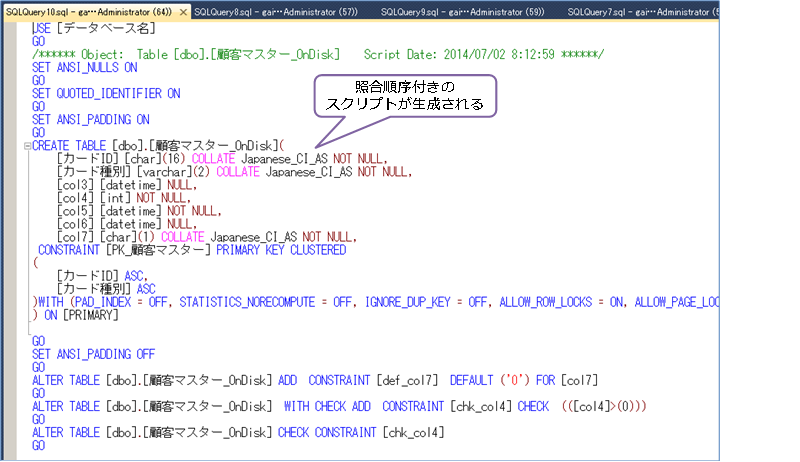
◆ スクリプト(CREATE TABLE ステートメント)の修正
次に、生成したスクリプトをもとに、メモリ最適化テーブルを作成するための CREATE TABLE ステートメントへ修正していきます。修正にあたっては、メモリ最適化テーブルを作成するためのルールを把握しておく必要があります。これは、次のとおりです。
- メモリ最適化テーブルでは、後からテーブル定義を変更することができない(ALTER TABLE ステートメントがサポートされていない)
- メモリ最適化テーブルでは、後からインデックスを追加することができない(CREATE INDEX ステートメントがサポートされていないので、CREATE TABLE でテーブルを作成するときに、インデックスを一緒に作成する必要がある)
- メモリ最適化テーブルでは、1つ以上の非クラスター化(NONCLUSTERED)のインデックスを作成するのが必須になる(SCHEMA_AND_DATA の場合は、PRIMARY KEY 制約が必須になり、PRIMARY KEY 制約にはインデックスが必須になる。SCHEMA_ONLY の場合は、インデックスが必須)
- メモリ最適化テーブルでは、ハッシュ インデックスまたは bw-tree インデックスがサポートされる(どちらも非クラスター化が必須。1つのテーブルで最大 8個まで)
- インデックスを作成する列には、NOT NULL が必須になる
- データベースの照合順序に Japanese_CI_AS(日本語版の SQL Server の場合の既定値)を利用している場合は、char/varchar データ型を nchar/nvarchar データ型へ変換する(∵より良い性能を出すため。詳しくは 2.12を参照)
- PRIMARY KEY 制約を設定する列が char 系のデータ型の場合には、BIN2 照合順序(Japanese_BIN2 や Latin1_General_BIN2 など)へ変更する
- ハッシュ インデックスを利用する場合は、バケット数(BUCKET_COUNT)を決定する(後からバケット数を変更することができない。バケット数の決定基準は後述)
以降では、上記の修正を 1つ1つ説明していきます。
◆ NOT NULL を付与 ~インデックスのキー列は NOT NULL が必須~
メモリ最適化テーブルでは、ハッシュまたは bw-tree インデックスを作成する列には、NOT NULL が必須になるので、生成されたスクリプトへ NOT NULL を付与しなければなりません。
また、PRIMARY KEY 制約には、インデックスの作成が必須になるので、PRIMARY KEY 制約を設定する列に対しても NOT NULL を付与する必要があります。
複合主キーなど、複数の列で PRIMARY KEY 制約やインデックスを構成する場合には、それらの列すべてに NOT NULL を付与する必要もあります。例えば、「顧客マスター」テーブルであれば、「カードID」と「カード種別」列で複合主キーを構成しているので、この 2つの列に NOT NULL を付与する必要があります。
( [カードID] [char](16) NOT NULL, -- NOT NULL を付与
[カード種別] [varchar](2) NOT NULL, -- NOT NULL を付与
[col3] [datetime] NULL,
:
NOT NULL を付与したということは、NULL 値を格納できなくなってしまうので、NOT NULL を設定した列には NULL 値があるかどうかをチェックしばければなりません。NULL 値がある場合には、それを別の値へ変更する必要も出てきます。また、アプリケーション側で NULL 値(ADO.NET なら DBNull.Value)を INSERT や UPDATE してる場合などは、それも修正していく必要があります。
今回のポイントカード システムでは、インデックスのキー列では NULL 値を利用していなかったので、特に修正は必要ありませんでしたが、別のお客様では、NULL 値を許可して、DEFAULT 制約(既定値)として NULL 値を挿入している場合がありました。このような列に対してインデックスを作成する場合には、DEFAULT 制約を変更したり、NULL 値の扱いについて、新しいルールを決定/変更していかなければなりません。
◆ char/varchar を nchar/nvarchar データ型へ変換(n付きへ変更)
メモリ最適化テーブルでは、(var)char データ型は、1252 コードページの照合順序でのみサポートされるので、「Japanese_CI_AS」照合順序では、(var)char データ型を利用することができません。(var)char データ型を利用したい場合には、COLLATE 句で 1252 コードページの照合順序(Latin1_General_CI_AS や Latin1_General_BIN2 など)を指定する必要がありますが、この照合順序では日本語データを格納することができません(詳しくは、2.12を参照)。
したがって、「Japanese_CI_AS」を利用するには n(var)char データ型(n 付きのデータ型)を利用しなければなりません。今回のポイントカード システムでは、char系の列には (var)char データ型を利用していたので、すべて n(var)char データ型へ変更しました。例えば、「顧客マスター」テーブルでは、「カードID」が char(16)、「カード種別」が varchar(2) だったので、nchar(16)、nvarchar(2) へ変更しています。
( [カードID] [nchar](16) NOT NULL, -- nchar へ変更
[カード種別] [nvarchar](2) NOT NULL, -- nvarchar へ変更
[col3] [datetime] NULL,
:
私は、クエリ エディターの「クイック置換」(Ctrl+H キー)機能を利用して、「char」を「nchar」へすべて置換して、その後「varnchar」(varchar が varnchar になってしまったもの)を「nvarchar」へすべて置換することで、この変更に対応しました。
◆ PRIMARY KEY 制約の設定(ハッシュまたは bw-tree インデックスの設定)
次に、PRIMARY KEY 制約を設定しますが、メモリ最適化テーブルでは、非クラスター化(NONCLUSTERED)のハッシュ インデックスまたは bw-tree インデックスの作成が必須になります。今回のポイントカード システムでは、すべての PRIMARY KEY 制約でハッシュ インデックスを利用しています。
ハッシュ インデックスを作成する構文は、次のとおりです。
HASH の後に、カッコで囲んでキー列を指定し、WITH 句で BUCKET_COUNT(バケット数)を指定します。バケット数の指針は、後述しますが、今回のポイントカード システムでは、マスター系のテーブル(カード マスターや顧客マスターなど)は、データ件数の約 3~4倍に設定しました(∵マスター系のテーブルは、データ件数の変動が少ないため)。トランザクション系テーブルに関しては、データ件数がどんどん増えていくので、将来増えるであろうデータ件数分の大きさに設定しました。
スクリプト生成では、「顧客マスター」テーブルは、次のように PRIMARY KEY 制約が生成されています(カードIDとカード種別の複合主キーで、クラスター化インデックスを作成)。
(
[カードID] ASC,
[カード種別] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
このうち、WITH 以下のオプション(PAD_INDEX や STATISTICS~、ON [PRIMARY] など)は、不要になるのですべて削除します。また、「カードID」と「カード種別」列の隣の「ASC」キーワード(b-treeインデックスの並び順を昇順に指示するキーワード)も不要になるので、削除します。
メモリ最適化テーブルでは、PRIMARY KEY 制約には非クラスター化(NONCLUSTERED)のインデックス(ハッシュまたは bw-tree)が必須になるので、次のように PRIMARY KEY 制約を設定します。
( [カードID] [nchar](16) NOT NULL,
[カード種別] [nvarchar](2) NOT NULL,
[col3] [datetime] NULL,
:
CONSTRAINT [PK_顧客マスター_2] PRIMARY KEY NONCLUSTERED
HASH ( [カードID], [カード種別] ) WITH (BUCKET_COUNT = 20000000)
変更しているのは、「CLUSTERED」を「NONCLUSTERED」、制約の名前(CONSTRAINT の隣)に「_2」を付与、キー列の前に HASH キーワードを入れてハッシュ インデックスを作成、WITH 句では BUCKET_COUNT のみを指定しています(バケット数は 2000万へ設定)。
制約の名前を変更している部分は、不要と思われる方もいらっしゃるかもしれませんが、今回は、既存のテーブルを残していて、そのテーブルに同じ名前の制約が存在しているので、違う名前へ設定しないと、テーブルの作成時にエラーとなってしまうため、「_2」を付与しています(付与する名前は任意なので、分かりやすい名前を付けておくことをお勧めします)。
◆ インデックスを作成する列が char系の場合は BIN2 照合順序へ変更
メモリ最適化テーブルでは、インデックスを作成する列が char 系のデータ型の場合には、BIN2 照合順序を利用しなければなりません。nchar/nvarchar データ型(n付き)を利用している場合には「Japanese_BIN2」、char/varchar データ型(1252 コードページ)を利用している場合には「Latin1_General_BIN2」などを利用します。
「顧客マスター」テーブルでは、「カードID」と「カード種別」列を「Japanese_BIN2」へ変更しています。
( [カードID] [nchar](16) COLLATE Japanese_BIN2 NOT NULL, -- 照合順序を変更
[カード種別] [nvarchar](2) COLLATE Japanese_BIN2 NOT NULL, -- 照合順序を変更
[col3] [datetime] NULL,
:
Japanese_BIN2 へ変更した場合は、既定の Japanese_CI_AS とは比較や並べ替え時の動作が変わることに注意が必要です(詳しくは 2.16 が参考になると思います)。
◆ DEFAULT 制約を設定、名前の変更
DEFAULT 制約を設定している場合は、次のように CREATE TABLE とは別途、ALTER TABLE ステートメントとしてスクリプト生成されることがあるので、これを CREATE TABLE の中の列定義へ移動します。
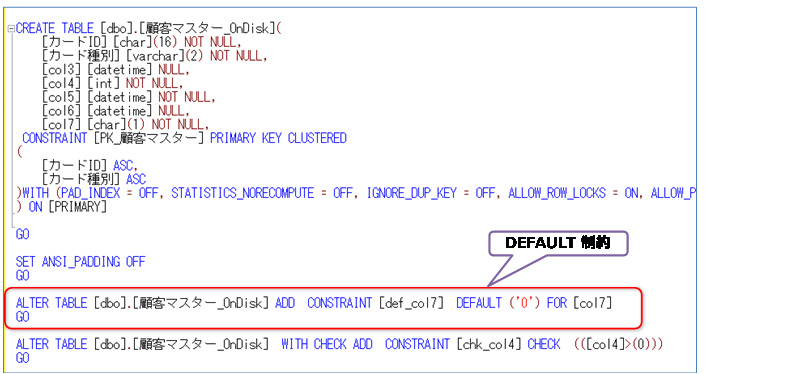
メモリ最適化テーブルでは、ALTER TABLE によるテーブル定義の変更がサポートされていないので、CREATE TABLE のときに、すべての定義を設定しておく必要があります。
「顧客マスター」テーブルの場合は、次のように col7 列へ DEFAULT 制約を追加しました。
( [カードID] [nchar](16) COLLATE Japanese_BIN2 NOT NULL,
[カード種別] [nvarchar](2) COLLATE Japanese_BIN2 NOT NULL,
:
[col6] [datetime] NULL,
[col7] [nchar](1) NOT NULL CONSTRAINT def_col7_2 DEFAULT ('0'), -- DEFAULT 制約
CONSTRAINT [PK_顧客マスター_2] PRIMARY KEY NONCLUSTERED
HASH ( [カードID], [カード種別]) WITH (BUCKET_COUNT = 20000000)
)
CONSTRAINT で指定している制約の名前は「_2」を付与して、既存の制約と名前が重複しないように変更しています。
◆ 追加のインデックスのスクリプト化
既存のディスク ベースのテーブルで、PRIMARY KEY 以外の列にインデックス(b-tree インデックス)を作成している場合には、インデックス定義をスクリプト化します(CREATE INDEX を自動生成)。スクリプト生成を行うには、次のように該当インデックスを右クリックして、[インデックスをスクリプト化]から[新規作成]の[新しいクエリ エディター ウィンドウ]をクリックします。
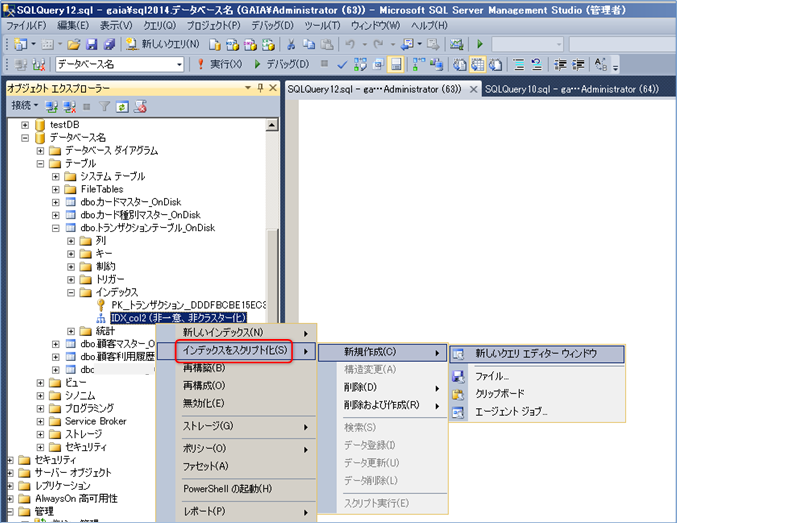
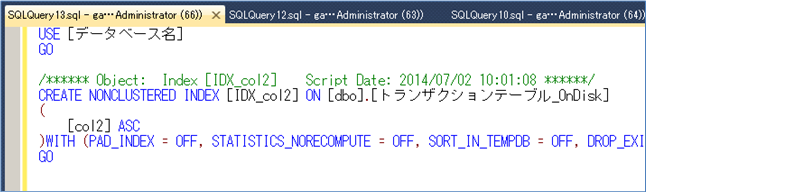
これにより、インデックスのキー列(どの列に対して作成されているか)が分かります。このディスク ベースのインデックスは b-tree インデックスなので、ハッシュまたは bw-tree インデックスへ変更して、CREATE TABLE でのテーブル定義へ含めるようにします。
◆ インデックスをハッシュまたは bw-tree へ変更
スクリプト生成したインデックス定義(CREATE INDEX)をもとに、ハッシュまたは bw-tree インデックスへ変更して、CREATE TABLE でのテーブル定義へ含めるようにします。
トランザクションテーブルでは、次のように 2つのインデックスを追加しています。
seq bigint IDENTITY(1,1) NOT NULL,
col2 データ型,
col3 データ型,
:
カードID nchar(16) COLLATE Japanese_BIN2 NOT NULL,
col29 データ型 NOT NULL,
col30 データ型 NOT NULL,
,INDEX IDX2 HASH (カードID) WITH (BUCKET_COUNT = 20000000)
,INDEX IDX3 HASH (col29, col30) WITH (BUCKET_COUNT = 20000000)
:
(カードID)にハッシュ インデックス、(col29, col30)にハッシュ インデックスを作成しています。このように、列定義の後(col30 までのデータ型や NULL 設定をした後)に、INDEX キーワードを付けて、インデックス名を指定し(上の例では IDX2 や IDX3)、HASH キーワードの後にインデックスのキー列をカッコで囲んで指定、WITH 句で BUCKET_COUNT(バケット数)を指定することで、追加のハッシュ インデックスを作成することができます。
◆ 利用できないデータ型
メモリ最適化テーブルでは、以下のデータ型がサポートされていません。
- 行サイズは、8060バイトが上限となり、varchar(max) や varbinary(max)、image、text などの LOB(ラージ オブジェクト)がサポートされない
- xml、sql_variant、datetimeoffset、hierarchyid、geography、geometry、rowversion、UDT(ユーザー定義データ型)がサポートされない
これらを利用している場合には、サポートされている別のデータ型へ置き換えられないかを検討する必要があります。例えば、varchar(max) を利用している場合には、データが 2000バイト以下のものしか格納されないと決まっているのであれば、varchar(2000) へ置き換えることができます。どうしても 8060バイト以上のデータを格納したい場合には、データを分割して格納するという方法もあります(第4章を参照)。
◆ 利用できない制約を削除する
メモリ最適化テーブルでは、CHECK 制約と FOREIGN KEY 制約がサポートされていません。したがって、これらの制約は、メモリ最適化テーブルからは削除しておく必要があります。
◆ データの永続化の決定(SCHEMA_AND_DATA/SCHEMA_ONLY)
メモリ最適化テーブルでは、データを永続化するかどうかを設定する必要があります(既定では、データが永続化されます)。データを永続化する場合は、SQL Server を再起動しても、データを復旧することができます。
データの永続化は、CREATE TABLE ステートメントの一番下の WITH 句で指定します。「MEMORY_OPTIMIZED = ON」で、メモリ最適化テーブルであることを指定して、「DURABILITY =」でデータを永続化するかどうか(SCHEMA_AND_DATA なら永続化する、SCHEMA_ONLY なら永続化しない)を設定します。
今回のポイントカード システムでは、すべてのテーブルで SCHEMA_AND_DATA を指定して、データを永続化しています。
「顧客マスター」テーブルでは、次のように作成しています。
( [カードID] [nchar](16) COLLATE Japanese_BIN2 NOT NULL,
[カード種別] [nvarchar](2) COLLATE Japanese_BIN2 NOT NULL,
[col3] [datetime] NULL,
[col4] [int] NOT NULL,
[col5] [datetime] NOT NULL,
[col6] [datetime] NULL,
[col7] [nchar](1) NOT NULL CONSTRAINT def_col7_2 DEFAULT ('0'),
CONSTRAINT [PK_顧客マスター_2] PRIMARY KEY NONCLUSTERED
HASH ( [カードID], [カード種別] ) WITH (BUCKET_COUNT = 20000000)
) WITH ( MEMORY_OPTIMIZED = ON
,DURABILITY = SCHEMA_AND_DATA ) -- データを永続化
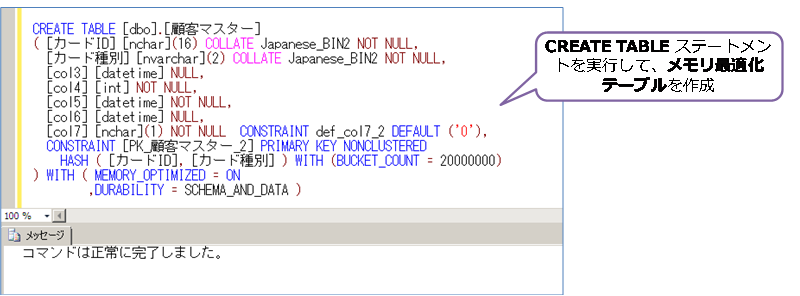
◆ CREATE TABLE ステートメントの実行して、メモリ最適化テーブルを作成する
スクリプトの修正が完了したら、CREATE TABLE ステートメントを実行して、メモリ最適化テーブルを作成します。


SQL Server 2016 の教科書(ソシム)



ASP.NET でいってみよう
第7刷 16,500 部発行
SQL Server 2000 でいってみよう
第12刷 28,500 部発行

SQL Server 2014 CTP2 インメモリ OLTP 機能の概要(Amazon Kindle 書籍)
(公開活動などのお知らせ)
第60回:SQL Server 2017 自習書 No.3「SQL Server 2017 Machine Learning Services」のご案内
第59回:SQL Server 2017 自習書 No.2「SQL Server 2017 on Linux」のご案内
第58回:SQL Server 2017 自習書 No.1「SQL Server 2017 新機能の概要」のご案内
第57回:SQL Server 2017 RC 版とこれまでのドキュメントのまとめ
第56回:「SQL Server 2016 への移行とアップグレードの実践」完成&公開!
第55回:書籍「SQL Server 2016の教科書 開発編」(ソシム)が発刊されました
第54回:「SQL Server 2016 プレビュー版 Reporting Services の新機能」自習書のお知らせ
第 53 回:SQL Server 2016 Reporting Services の新しくなったレポート マネージャーとモバイル レポート機能
第 52 回:SQL Server 2016 の自習書を作成しました!
第 51 回:PASS Summit と MVP Summit で進化を確信!
第 50 回:新しくなった Power BI(2.0)の自習書を作成しました!
第49 回:Excel 2016 の Power Query を使う
第 48 回:新しくなった Microsoft Power BI ! 無料版がある!!
第 47 回:「Microsoft Azure SQL Database 入門」 完成&公開!
第 46 回:Microsoft Power BI for Windows app からの Power BI サイト アクセス
第 45 回:Power Query で取得したデータを PowerPivot へ読み込む方法と PowerPivot for Excel 自習書のご紹介
第44回:「SQL Server 2014 への移行とアップグレードの実践」ドキュメントを作成しました
第43回:SQL Server 2014 インメモリ OLTP 機能の上級者向けドキュメントを作成しました
第42回:Power Query プレビュー版 と Power BI for Office 365 へのクエリ保存(共有クエリ)
第41回:「SQL Server 2014 CTP2 インメモリ OLTP 機能の概要」自習書のお知らせです
第40回: SQL Server 2012 自習書(HTML版)を掲載しました
第39回: Power BI for Office 365 プレビュー版は試されましたか?
第38回: SQL Server 2014 CTP2 の公開
第37回: SQL Server 2014 CTP1 の自習書をご覧ください
第36回: SQL Server 2014 CTP1 のクラスター化列ストア インデックスを試す
第35回: SQL Server 2014 CTP1 のインメモリ OLTP の基本操作を試す
第34回: GeoFlow for Excel 2013 のプレビュー版を試す
第33回: iPad と iPhone からの SQL Server 2012 Reporting Servicesのレポート閲覧
第32回: PASS Summit 2012 参加レポート
第31回: SQL Server 2012 Reporting Services 自習書のお知らせ
第30回: SQL Server 2012(RTM 版)の新機能 自習書をご覧ください
第29回: 書籍「SQL Server 2012の教科書 開発編」のお知らせ
第26回: SQL Server 2012 の Power View 機能のご紹介
第25回: SQL Server 2012 の Data Quality Services
第24回: SQL Server 2012 自習書のご案内と初セミナー報告
第23回: Denali CTP1 が公開されました
第22回 チューニングに王道あらず
第21回 Microsoft TechEd 2010 終了しました
第20回 Microsoft TechEd Japan 2010 今年も登壇します
第19回 SQL Server 2008 R2 RTM の 日本語版が公開されました
第18回 「SQL Azure 入門」自習書のご案内
第17回 SQL Server 2008 自習書の追加ドキュメントのお知らせ
第16回 SQL Server 2008 R2 自習書とプレビュー セミナーのお知らせ
第15回 SQL Server 2008 R2 Reporting Services と新刊のお知らせ
第14回 TechEd 2009 のご報告と SQL Server 2008 R2 について
第13回 SQL Server 2008 R2 の CTP 版が公開されました
第12回 MVP Summit 2009 in Seattle へ参加